

Hulu/Disney Streaming Hadoop3升级实践
1 引言
Hadoop 3 发布已有 5 年,最新版本已经更新到 3.3.2。在这 5 年中,Hadoop 发布了许多重大特性。HDFS EC 编码趋于成熟,在提升容错的前提下降低了存储空间;HDFS RBF 简化了客户端的配置,平衡了 amenode 负载;多 Standby Namenodes 的支持进一步增加容错;Yarn 增加对 docker 的支持,提供更好的隔离性;增加动态配置资源的 API,Federated 的支持提高了集群的扩展性。
hadoop在hulu的部署
在介绍 Hadoop 升级之前,我们先来看一下升级前的集群架构。Hulu 的 Hadoop 集群已经在 2.6.0-cdh5.7.3 上运行多年,整体的结构如下图所示。
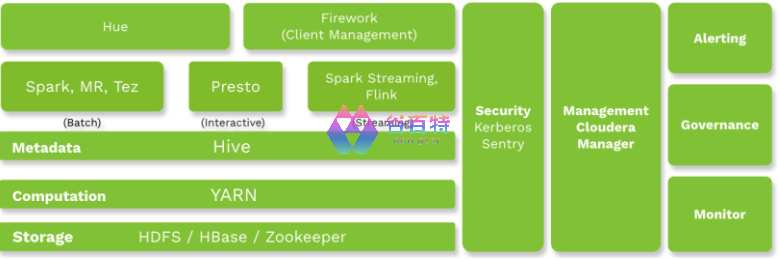
图 1:Hulu 大数据集群架构
可以看到 HDFS,Yarn,Hive 为整个集群提供了存储、计算、和元数据服务,是支撑上层应用的核心组件。整个集群有大约数千台服务器,数百 PB 数据。集群访问通过 Firework 客户端控制。Firework 是一个封装了开源客户端和集群配置的工具,支持动态拉取集群配置,动态更新客户端版本,是所有 Query 和 App 提交的入口,也为我们在升级过程中获取用户 APP 的提交记录提供了诸多便利。
升级背景
此次 Hadoop 的升级涵盖了几乎所有的相关组件,包括 Cloudera,HDFS,Yarn,Hive,Hbase,Zookeeper,Sentry 等。由于受到 license 的限制,我们从 2.6.0-cdh5.7.3 升级到 3.0.0-cdh6.3.3(注,CDH6 商业版有额外的支持周期)。
我们从 2021 年第二季度开始测试,到 7 月份正式上线,历时 4 个月时间。HDFS,Yarn,Hive 作为升级的核心组件,我们对其进行了详细的测试。其他组件的升级暂且不在本文中介绍。
在升级过程中我们尽可能地平衡升级的复杂度与对用户的影响。在 Hulu,Hadoop 的主要用户分布在美国西海岸时区和北京时区,少量在美国东海岸。受疫情影响,大多数 office 依然在关闭状态,协调工作会更加困难。因此我们需要考虑在升级前后保证用户的 App 在不替换 Hadoop 依赖的情况下能够运行最新的集群,尽可能地减少或者延后升级带来的变动。
因此,在升级过程中我们增加了只依赖 Hadoop2 的兼容版本,使得用户端依赖的升级可以延后进行。这个版本在所有用户升级到新的 Hadoop3 依赖后被淘汰掉 。整个过程的时间线如图 2 所示。
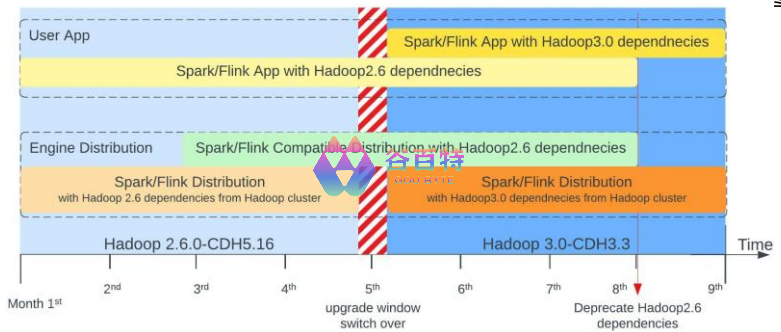
图 2:Hadoop 升级规划
由于 Cloudera 不提供滚动升级的方案,只提供停机升级和迁移升级。我们在前人的经验基础上,探索了新的升级方案。
2 兼容性问题
在升级过程中,Hadoop 各个服务的兼容性从以下四个方面考虑:
客户端与服务之间的接口兼容性
服务各个组件之间的接口兼容性
各个组件与其存储状态的兼容性
用户接口在语法和语义上的兼容性
Hadoop3 的升级过程中的兼容问题已经有很多技术博客讨论,我们在升级过程中也参考了这些经验,对上述问题进行了一一验证。下面针对我们在实际升级过程中各个组件遇到的额外问题,做一个补充。
hdfs兼容性问题
HDFS Client 以及各个组件之间接口兼容良好。组件之间的问题在《HDFS3.2 升级在滴滴的实践》一文中有详细的介绍。其中 FSImage 的兼容问题的 patch 已经打在了 CDH6.3 的发行版中。
在我们的实践中,发现仍有两个问题,一是 HDFS Namenode 与 Datanode 之间的 Block Access Token 在 2.7 中增加标识 storage type 的字段(HDFS-6708),这导致启用 security 后 Hadoop 2.6 与 3.0 在协议上会有兼容性的问题,因此需要升级之前在 2.6 中打上 HDFS-15191。另一个是 Datanode 存储目录结构的变化,Datanode 在 2.8(HDFS-8791)中修改了 block 的目录的 hash 结构,将 256*256 个目录改为 32*32 个以改善在 ext4 文件系统上的性能。
由于我们从 2.6 直接升级到 3.0 会受到这个变化的影响,在 Datanode 的滚动升级过程中,我们计算了 block 新的目录结构,在 Datanode 启动之前,将 block 移动到正确的目录上。
除了上述问题以外,在 HDFS 的命令行客户端上,chmod 命令对 sticky bit 的用法有轻微的修改(HDFS-10689), 客户端不再支持 HADOOP_HEAPSIZE 和 JAVA_HEAP_MAX, 而是用 HADOOP_HEAPSIZE_MAX 和 HADOOP_HEAPSIZE_MIN 来调整客户端内存。
yarn兼容性问题
Yarn 各个组件以及客户端与服务端之间的兼容性问题在[1]中有很详细的介绍。其中对于 YARN-668 中将 token identifier 的序列化协议改为 Protocol Buffer 后引起的兼容问题,YARN-8310 做了向下兼容,且这个 patch 已经包含在 CDH6 中。但是它仅能够使得 Hadoop3 的 Yarn 能够解析 Hadoop2 的 token,认证依然会失败。这是由于 token 中用 byte arrary 表示的 token identifier,如果是由 Hadoop2 的 RM 生成,在 Hadoop3 中经由反序列化、序列化之后的结果与原始 byte array 不一致。服务端会用密匙计算这个 byte array 的签名,然后与 Token 中的签名对比,如果不一致则会认证失败。这个问题与 HDFS-15191 解决的问题类似,需要增加一个 cache 用来存储并返回原始的 byte array。
另外,从 Hadoop 2.6.1 开始,同一 NodeManager 节点只能打一个 label,如果存在 Nodemanager 拥有多个 Label,在升级之前需要对 Queue 和 Node 的映射关系进行调整,但是在 CDH5-2.6.0 中没有这个限制。
hive兼容性问题
CDH5 中 Hive 一直使用 1.2 版本,已经十分老旧,在 CDH6 中终于升级到 Hive 2.1。虽然距离最新的 Hive 3 依然有一定的差距,但是在性能和稳定性都得到了很大的改善。在 2.1 中,Hive 的存储表结构的元数据发生了的变化,升级过程需要在停止服务的前提下将元数据升级到新的版本。Hive 的 SQL 也在这个版本中有很多变化 [6],具体总结如下
RLIKE (A, B) 不再支持,该用 A RLIKE B
反引号之内的点被识别为表名的一部分,从而报错。如 create table
schema_name.new_table需要被改为 create tableschema_namenew_tableUnion All 不再支持类型的隐式转换
UNION ALL 不再支持在自查询上进行 SORT BY, CLUSTER BY, ORDER BY, LIMIT, 以及 DISTRIBUTE BY
GenericUDF.getConstantLongValue 被 deprecated
增加保留的关键字,如 TIME,HOUR
语
desc table.column_name不再支持,仅能够使desc table_name column_name不再支持 ALTER TABLE 中的 OFFLINE 和 NO_DROP 标志
在 Hive 增加的保留关键字中,hour、day 等已经在线上被广泛 di 用作 partition key。这个变化意味着大量的列名或者客户端的 SQL 语句需要改变。我们 revert 了 Hive 中相关关键字以避免升级过程中大量的用户程序修改。
spark兼容性问题
目前在我们的集群中大部分的线上 Spark app 主要使用社区 2.3,2.4 版本,社区 Spark 2.x 主要依赖 Hive1.x 和 Hadoop2.x 进行编译。在升级到 Hadoop3.0+Hive2.1 后,虽然 Spark 2.x 中的 Hive1.x 客户端与 Hive2.x 服务端之间保持兼容,但是 Hadoop3.x 的依赖包与 Hive1.x 之间存在冲突。虽然 Spark3.x 能够使用 Hive2.x 和 Hadoop3.x,但是升级 Spark 也需要用户端进行适配工作。
为了继续支持 Spark 2.x,需要打上 HIVE-15016,HIVE-16081,HIVE-16131。这几个 patch 中的文件目录结构发生了变化,需要在理解 patch 的基础上手动打到 hive1.x 的分支中。同时需要修复 JvmPauseMonitor 接口变化造成的编译错误
此外,MR 主要由 Hive 提交,主要通过 HiveSQL 生成,版本随升级切换,不需要考虑兼容行问题。Flink 则与 Hive2.x,Hadoop3.x 工作良好。
3 App包依赖问题
在上一章,我们讨论了 Hadoop 各个服务之间、服务内组件之间、客户端与服务之间接口上的兼容性问题。尽管可以解决接口上的冲突,但是由于 Hadoop 生态复杂的依赖,依然可能与用户的 Jar 包在升级过程中产生冲突。为了满足图 2 中用户延后升级 App 端依赖,我们对 Spark 和 Flink 加载 Jar 包的过程进行了详细的分析。
对于升级过程中可能的依赖问题,我们可以分为三类:
用户 App 的 Assembly Jar 中引入 hadoop 依赖并开启 user class first(在 Spark 中为 spark.driver.userClassPathFirst 和 spark.executor.userClassPathFirst; 在 Flink 中为 classloader.resolve-order=“child-first”,这也是 flink 的默认配置)
用户 App 与 Hadoop 依赖相同的第三方包,并且升级后 Hadoop 与用户 App 的版本之间无法兼容
SPI 机制造成的调用错误
spark和flink的classloader
在介绍上述问题之前,我们先来理解 Spark 和 Flink 用户任务线程中 Jar 包加载机制。JVM 中 ClassLoader 加载类的原理可以参考[4]。Spark、Flink 包含自定义的 ClassLoader,并将其设置到用户任务线程的 contextClassLoader 中,如图 3 所示。
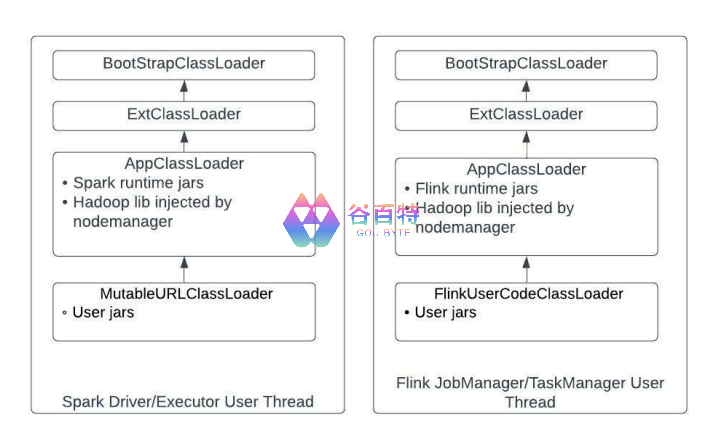
图 3:Spark,Flink 的依赖包加载
所有的 Classloader 由类成员 parent 连接起来形成一个链表。其中 AppClassloader, MutableURLClassLoader,FlinkUserCodeClassLoader 均继承自 URLClassLoader,并且按照内部存储的 URL 列表加载 Jar 包,因此排在前面的 Jar 包实际上会先被搜索,不过 JVM 规范并不承诺这一点。而 BootStrapClassLoader 和 ExtClassLoader 主要管理 JVM 的 runtime 包和相关扩展包。
AppClassLoader,MutableURLClassLoader,FlinkUserCodeClassLoader 管理的 Jar 包大致可分为三类:
用户 App 的 Jar 包。Spark 中由命令行第一个 Jar 包,--jars,spark.yarn.dist.jars, spark.yarn.dist.archives 等决定。Flink 中由命令行中第一个 Jar 包或 --jarfile 决定
Spark,Flink 分发在 HDFS 上的 runtime jar 包。在 Spark 中,由 spark.yarn.archive,spark.yarn.jars, 以及环境变量 SPARK_HOME 决定。在 Flink 中,由 yarn.provided.lib.dirs 和环境变量 FLINK_LIB_DIR 决定
系统环境中的 Hadoop 相关的 Jar 包。在 Spark 中, 由 yarn.application.classpath, mapreduce.application.classpath 决定。Flink 仅加载 yarn.application.classpath。这两个参数的默认值是由一组环境变量定义,如 HADOOP_HDFS_HOME, HADOOP_YARN_HOME 等。这些环境变量在 application 运行时,由 NodeManager 注入。
默认情况下,MutableURLClassLoader 与一般的 URLClassLoader 的类加载顺序相同,都会先加载 parent 中的类,当开启 user class first 时,则会优先加载自身管理的 Jar 包。而 FlinkUserCodeClassLoader 默认情况下则是用其子类 ChildFirstClassLoader 代替,与 Spark 默认情况相反。在 Flink 的 per-job 模式下,Flink user jars 的加载用的 ClassLoader 和加载顺序受 yarn.per-job-cluster.include-user-jar 参数的影响,默认情况下加载在 AppClassLoader 中,按包名的字典序排列。
用户jar引入Hadoop依赖的问题
一般用户 App 端主要依赖 Spark,Flink 的编程接口,因此用户的 Assembly Jar 中常常仅包含了 Spark/Flink 客户端的依赖包。当 App 提交到 Yarn 上后, 容器启动入口类依然多从升级后系统提供的包中加载。如果用户开启 user class first,用户的 Jar 包中包含的 Hadoop2 的类会覆盖一部分 Hadoop3 的类,在调用过程中会出现 Hadoop2,3 类之间的内部调用,非常容易抛出 MethodNotFound 异常。因此对于开启了 user class first 的 App 均需要将 hadoop 相关的依赖在 pom 中设置为 provided,或者提前在 hadoop3 上进行测试解决兼容性问题。
第三方包冲突
Hadoop 大版本的升级的同时也更新了其众多第三方依赖包,如果存在用户依赖的第三方包已不再向下兼容,有可能产生冲突。虽然这类问题可以通过 Maven Shade 等插件解决,但是 Hadoop 生态的依赖包数量十分巨大,而用户依赖具有不确定性,难以提前确定需要 shade 的类。
为了向前兼容,我们在集群中分发了一个向前兼容的 Spark 和 Flink 版本。兼容版本中包含 Hadoop2 的完整依赖,通过 3.1 中对 ClassLoader 中 Jar 包的加载顺序的分析,Hadoop3 的依赖会被完全覆盖。在解决第二章的兼容性问题后,这个版本对于大部分用户 App 来说都够正常在 Hadoop3 的环境中工作。然而,SPI 的存在使得 App 依然有可能发生调用错误,我们在下一节介绍。
SPI机制造成的调用错误
SPI(Service Provider Interface)[5]常常被用于反射机制中,在 Hadoop 包中也有大量使用。反射机制的存在,会使得在 ClassLoader 加载链上被覆盖的 Jar 包中的类也有机会得到加载,从而引发错误。
我们通过一个例子来说明。为了能使集群中运行不同的 Spark,Flink 版本,我们在 firework 中提交 Spark 和 Flink 时加载了 HDFS 上不同版本对应目录下的 runtime jar 到 container 的 CLASSPATH。在早期测试中,这些目录中的 assembly jar 包含了所有的依赖并覆盖了 CDH 系统中原本的 Jar 包来解决 3.3 中提到的问题。由于 HDFS 的接口在 2 和 3 之间是兼容的,因此 assembly jar 中 Hadoop client 保持了 2.6。结果,有用户提交 job 时发现所有 http 协议通过 java URL 打开资源时,handler 被替换为 hadoop 中的 HttpFileSystem 而出错。这个 HttpFileSystem 仅用于通过 http 协议访问 HDFS 上的文件,但是结果是针对非 HFDS 上的资源,java URL 也被设置成了用 HttpFileSystem 处理。
问题的起因在于 Spark 的 SharedState 初始化过程中,设置了 URL 的 handler 工URL.setURLStreamHandlerFactory*(new FsUrlStreamHandlerFactory()), FsUrlStreamHandlerFactory 初始化过程中会加载 FileSystem 的子类及其支持的 URL schema,并在访问 URL 时根据 URL 的 schema 调用对应的子类,而 FileSystem 子类的加载过程的第一步便是通过 SPI 查找配置在 Jar 包中 META-INF/services/org.apache.hadoop.fs.FileSystem 里的 Provider。在 2.6 中,FsUrlStreamHandlerFactory 会加载 FileSystem 返回的所有子类,但是 Jar 包中没有配置 HttpFileSystem。在 3.0 中,FsUrlStreamHandlerFactory 会忽略掉支持 http 和 https 协议的 FileSystem 子类,但是 Jar 包中配置了 HttpFileSystem。这两个包单独运行都不会加载 HttpFileSystem 到 java 的 URL 类中。当他们同时存在时,SPI 机制会将 ClassLoader 及其所有父节点可加载的包中的 provider 的配置文件进行合并,尽管我们用 2.6 的版本完全覆盖 3.0 的版本,FsUrlStreamHandlerFactory, FileSystem 和 HttpFileSystem 也都加载为 2.6 版本,但配置在 Hadoop 3 中的 provider 生效了,而 2.6 版本的 FsUrlStreamHandlerFactory 则读取了合并后的 provider 列表,URL 中默认打开 http 协议的类被替换为 HttpFileSystem。
SPI 造成的问题非常复杂,也意味着通过反射机制,被覆盖的包依然可以改变实际加载的包的行为。因此为了使兼容版本的 Spark 和 Flink 能够工作,我们在升级过程中保留了 CDH5 在系统中的包,同时在兼容版本提交 Container 的 ApplicationSubmissionContext 中将所有的 CDH6 包替换为 CDH5 包的路径。由此在 hadoop3 集群中生成一个完全只依赖 Hadoop2 的环境。由于接口上的兼容,运行在兼容版本的 App 能够正常在 hadoop3 的环境中工作。
4 升级
升级测试
测试过程共分为 5 轮,三个阶段。
二轮测试,兼容性测试,解决发现的问题以及打上 patch
四轮测试,压力测试。在 100 个节点左右的测试集群上采样线上的数据和任务,并进行压测
上线前演练
在前两轮的测试中,重点针对兼容性问题进行测试。我们通过 firework 客户端和服务端 audit 日志,收集了所有用户的提交命令,jar 包,query,和环境变量。对使用了不兼容的关键词的 query 进行了粗筛,并通知对应的用户在 Hadoop3 的集群中进行测试,对不兼容的 query 进行修改。
升级过程
升级过程分为三个阶段。
我们首先升级 Cloudera,Sentry,Zookeeper 等组件。这些组件与升级前的版本兼容良好,没有 downtime。
然后,由于 Hive 的 metadata 已经不再兼容,升级采用停机升级。在停机的状态下升级 metadata,然后重新拉起服务。由于在 Hive 停机的状态下,大部分 Yarn 上的 app 无法正常工作,因此我们在这个过程中对 Yarn 也进行了了停机升级。在 Yarn 升级的过程中,我们清除了 Yarn 上 application 以及 NM 本地的所有状态。基本上重新搭建了 Yarn 服务。整个过程大约花费 2 个小时。
最后,HDFS 采用 Rolling Upgrade。按照 JournalNode,Namenode,Datanode 的顺序依次滚动升级。线上的 6 个 namespace 每个升级大约 2 个小时。Datanode 则按照机架依次升级,花费了 3 周左右的时间。
5 总结
本次升级整体比较顺利,我们也由此对大数据的整个架构有了更进一步的了解。但是,本次升级仍与社区的最新版本 3.3 有一定的差距,在稳定性和性能方面依然有诸多地方可以优化。随着容器化技术的成熟,隔离性上还有很大的改进空间,App 的依赖问题也能够由此彻底解决。在 Hive 升级之后 Spark 也能够 release 更新的版本。与云上服务更友好的集成会是未来的方向之一。
6 参考文献
[1] Hadoop2.6 升级到 3.2 在 58 同城的实践. https://mp.weixin.qq.com/s/LqbTNa7ZA_InL843eDP5_w
[2] HDFS3.2 升级在滴滴的实践. https://mp.weixin.qq.com/s/bv9NHFPLCCAV_IYIi4FQ8g
[3] Apache Hadoop3.3.2 – HDFS Rolling Upgrade. https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsRollingUpgrade.html
[4] 一看你就懂,超详细 java 中的 ClassLoader 详解.https://blog.csdn.net/briblue/article/details/54973413
[5] Introduction to the Service Provider Interfaces. https://docs.oracle.com/javase/tutorial/sound/SPI-intro.html
[6] Incompatible Changes in CDH 6.3.3. https://docs.cloudera.com/documentation/enterprise/6/release-notes/topics/rg_cdh_633_incompatible_changes.html#hive_hos_hcatalog_ic_631
评论区