

Hadoop3.x 中增加了很多特性和重大改进。在 HDFS 方面,最主要是 EC 能力成熟,显著降低 HDFS 数据存储成本。在 Yarn 层面,支持多集群 Federation,可以有效利用多 YARN 集群空闲资源,达到降本增效的目标。此外,还有大量其他新的特性,有效提高集群的稳定性及效率,降低运营成本。
一 升级背景
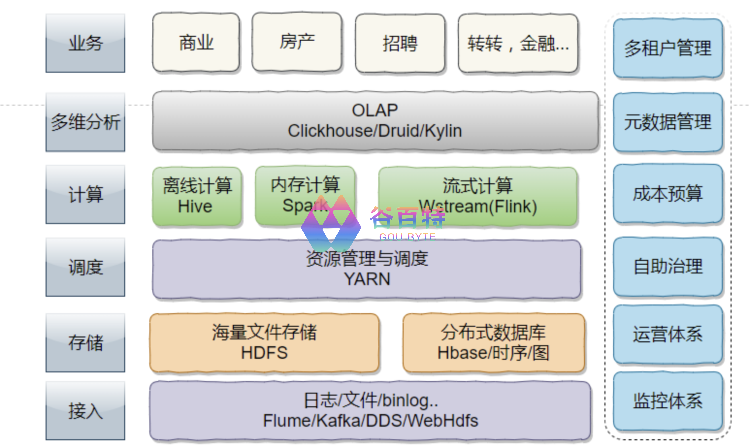
以上是 58 同城数据平台部架构,可以看出,Hadoop(包括 HDFS 和 Yarn)作为 58 大数据平台最基础最核心的组件,承载了整个 58 的离线数据存储和计算资源的调度。
 本文会从 HDFS/Yarn/MR3 等 3 个层面的来说明 Hadoop3.2.1 在 58 的升级实践。
本文会从 HDFS/Yarn/MR3 等 3 个层面的来说明 Hadoop3.2.1 在 58 的升级实践。
二 hdfs升级
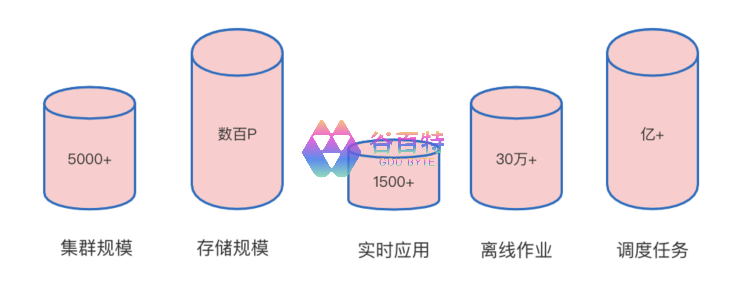
从 2020 年初开始,我们就开始推进 HDFS 的版本升级,并在 2020 年第二季度,在完成调研、代码整合和兼容性测试后,我们将 HDFS 从 2.6.0-cdh5.4.4 升级到了 3.2.1。由于我们没有用来升级过渡的小集群,最终直接将我们的离线大集群(5000+ 规模)HDFS 升级到了 3.2.1。
1、升级梳理
由于我们现在 Hadoop 版本为 2.6.0,和 3.2.1 版本之间存在较大的差距,升级 HDFS 存在较多的未知风险,需要调研梳理的工作比较多,我们从以下 5 个方面进行了重点梳理:
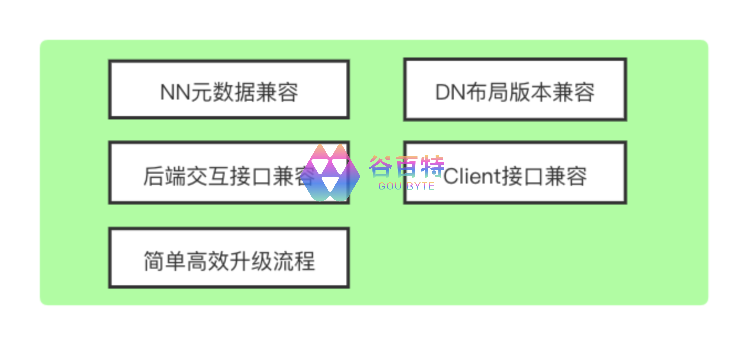
① NN 元数据兼容:保证升级过程中,如果主服务升级失败后可以降级到旧版本,这里的元数据包括 FSImage 和 EditLog。为了解决 2.6.0 到 3.2.1 的元数据兼容性问题,我们回滚了 HDFS-14831 中描述的问题。
② DN 布局版本兼容:新旧版本 DN 之间布局版本不能有太大变化,需要保持兼容,这样才能保证 DN 在升级时如果遇到问题还能降级回旧版本。但是从 2.6.0 到 3.2.1,DN 上的数据块存储目录结构发生变化,从 256x256 变成了 32x32 个目录,以解决 DN 在 Ext4 文件系统中用 256x256 个目录存储数据块的性能问题。为了兼容,我们回滚了这个提交。
③Client 接口兼容:由于 HDFS 被太多的组件(MR/Spark/Flink/Kylin/Flume/Druid 等)使用,要同步升级每个组件的 HDFS Client 有太多工作要做,我们最终只选择升级 HDFS 后端服务,包括 NN/JN/ZKFC/DN。所以需要保证 2.6.0 的客户端可以正常访问 3.x 的 NN 和 DN 服务。经过梳理测试,2.6.0 版本的客户端访问 3.2.1 版本的服务端是完全兼容的。
④ 后端交互接口兼容:在升级过程中存在新旧 NN/ 新旧 JN/ 新旧 ZKFC/ 新旧 DN 等中间状态,这就要保证新旧版本服务之间接口要兼容。经过测试,后端服务的交互接口都是兼容的。
⑤ 简单高效的升级流程:跨大版本升级也尽可能做到和小版本升级一样的简单,方便运维操作。梳理了 HDFS 自带的滚动升级流程,发现有一些不方便的地方,比如滚动升级期间会生成一个回滚的 FSImage 文件,DN 端保存删除的数据块等,我们对 HDFS 自带的滚动升级流程进行了改造,使得 HDFS 从 2.6.0 到 3.2.1 的跨大版本升级流程可以和我们之前在 2.6.0 的小版本升级一样简单可控。
2、代码整合
在 Hadoop 2.6.0 版本中,我们针对 HDFS 开发了很多的特性,包括安全体系、NN 性能优化,DN IO 优化及定制化 issue 等,我们将这些定制的特性全部整合到了 3.2.1 版本中。
3、测试
由于 HDFS 跨大版本升级存在较大的难度和风险性,我们进行了尽可能全面的测试,包括:
① Client 接口兼容性测试:包括现网全类型任务、全量 SQL,以及部分业务核心任务测试;
② 滚动升级测试:进行多次滚动升级测试,保证了滚动升 / 降级中新旧版本 NN 元数据的兼容性、新旧 DN 布局版本的兼容性、以及后端服务接口在不同状态的兼容性;
③、3.2.1 NN 性能测试:在测试环境保持现网配置和现网集群元数据压力情况下,3.2.1 版本的 NN 读写元数据性能可以达到现网性能要求,保证了升级后 NN 性能不会成为瓶颈。
4、上线
我们的 HDFS 升级分为成了两个阶段:
① 主节点升级阶段:
升级流程为:JN-->NN-->ZKFC,4 组 NS 升级花了 1 周多时间,升级整体相对顺利。
② DN 升级阶段:
在主节点升级完成后,我们在一个月内完成了 5000+ DN 节点的升级。
由于我们简化了滚动升级流程,不需要太多的运维介入操作,使得我们的升级更加简单顺利。
在 HDFS 升级到 3.2.1 后,我们落地了新版本中的两个重大特性:RBF 和 EC,并都取得了很好的效果,接下来我们会重点介绍。
5、ViewFS切换到RBF
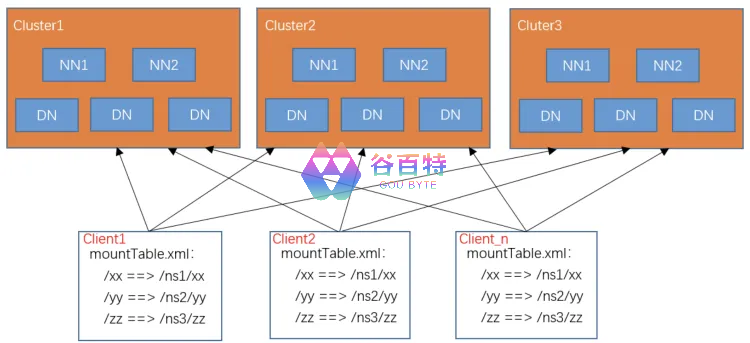
在 Hadoop2.6.0 版本中,我们使用基于客户端的 ViewFS 路由来实现多 NS 的访问,但是随着业务增长,集群规模越来越大,NS 越拆越多,基于客户端 ViewFS 的方式存在以下几个明显缺点:
① 挂载表信息非集中式管理,变更维护时很难保证客户端的一致性②、挂载表信息变更时,部分依赖服务需重启才能生效,变更代价大③、ViewFs 挂载点不支持挂载到多个集群,在线跨集群迁移数据困难
ViewFS 架构如下:
从 Hadoop 2.9.0 版本开始,社区提供了新的解决方案,即 RBF,并在最新 Hadoop 3.3.0 发布版中变得稳定,RBF 架构如下:
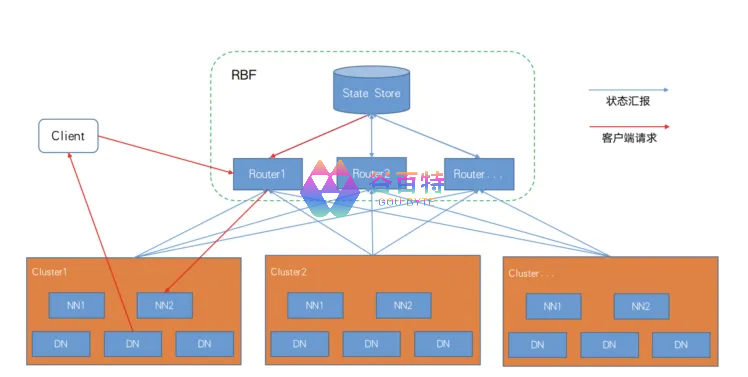
分析 RBF 的架构和原理,相对 ViewFS 存在的优势:
① 挂载表信息集中式管理,不存在不一致的情况
② 挂载表信息变更实时生效,对服务透明,不用重启服务
③ 挂载点支持挂载多个集群,数据跨集群在线迁移变得容易
④ 支持全局 Quota,实现联邦模式下的全局 Quota 管理
想要切换到 RBF,必须考虑我们的现网情况,社区并没有从 ViewFS 透明切换到 RBF 的解决方案,需要我们自己实现,我们从以下几个方面进行了优化:
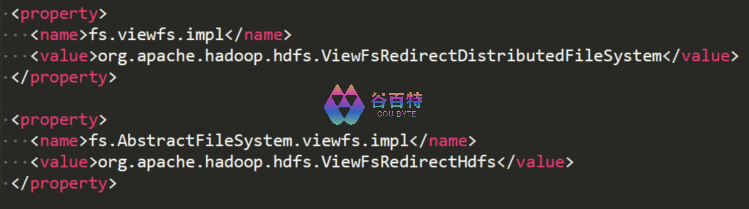
(1)、用户透明访问 RBF
为了实现用户访问透明的从 ViewFS 切换到 RBF,我们自定义了两个类:ViewFsRedirectDistributedFileSystem.java 类(继承 DistributedFileSystem.java 类)和 ViewFsRedirectHdfs.java 类(继承 Hdfs.java 类),保证了 ViewFS 请求透明切换到 RBF,并通过配置让这两个类来生效:
(2)、自定义写集群策略
RBF 其中一个强大能力是支持一个挂载点挂载到多个集群,这样使得业务数据能够跨集群存储和数据在线迁移,原生提供了多种写集群选择策略:
① RANDOM:随机选择
② LOCAL:本地优先选择
③ HASH_ALL:完全哈希方式选择
④ HASH:局部哈希方式选择
⑤ SPACE:基于可用空间选择
但是以上策略都不能满足我们现在和未来数据迁移的需求,所以我们自定义了两个策略:
① FIRST:挂载点挂载多个集群时,新数据写到第一个集群,数据同时从两个集群访问
② LAST:挂载点挂载多个集群时,新数据写到最后一个集群,数据同时从两个集群访问
(3)、重点业务访问隔离
对重点业务我们需要做到访问隔离,在切换到 RBF 后,对所有联邦子集群的 HDFS 访问请求都会经过 Router 转发,如果某个子集群响应变慢,进而反压到 Router 端,会导致通过 Router 访问其他子集群的请求也受到影响,这增加了上线 RBF 的风险,我们针对这个风险点也做了一些工作,包括:
① 分组管理 Router:重点业务使用单独的一组 Router,在客户端将重点业务的 HDFS 请求自动转换到单独的一组 Router。
客户端配置:

通过以上配置就可以将某个业务对子集群 ns1/ns2/ns3,以及默认 rbf-ns 的请求切换到 rbf-x-ns 了,rbf-x-ns 对应的 Router 为单独的一组 Router。
② 对 Router 服务进行改造,实现和 FCQ 类似的功能,参考:HDFS-14090
(4)、其他优化
除了以上三点优化外,我们还对 3.2.1 版本的 RBF 进行了若干的优化和 BUG 修复,包括:
① 修复服务认证访问失败 BUG
② 修复 Router 不能传递客户端 IP 到 NN 的 BUG(HDFS-16254)
③ 修复通过 Router 访问 NN,导致 NN 白名单机制失效 BUG
④ 修复通过 Router 来创建目录,出现目录权限有误的 BUG
⑤ 挂载表修改时即时更新所有 Router(HDFS-13443)
⑥ 安全模式下拒绝读请求
⑦ 去掉 getDataNodeReport 请求:避免对 NN 造成较大压力
⑧ 修复 UI 错误的统计信息等
6、EC落地
社区对 EC 的开发分为两个阶段,第一阶段支持条形布局,以更友好的支持小文件的 EC 转换,第二阶段支持连续布局。目前第一阶段的功能已经可用,第二阶段还处于规划阶段。我们基于条形布局来落地 EC,基于条形布局的 EC 支持在线文件转换,比如对新写入文件直接转换为 EC 模式,也支持离线转换,但是考虑到读取 EC 数据时会有大量的跨节点带宽和 EC 数据损坏恢复时会消耗更多 CPU,我们只使用了离线 EC 转换方式,也就是只对冷数据进行 EC 转换。
为了落地 EC,我们做了以下几项准备工作:
(1)、客户端支持 EC 数据读 / 写
在落地 EC 时,我们的 Hadoop 客户端和 Yarn 集群都是 2.6.0 版本,需要改造 HDFS 客户端以支持 EC 数据读 / 写。
(2)、distcp 支持 EC 数据转换
EC 一期的实现是基于条形布局的,普通数据块转换为 EC 模式,需要进行一次数据拷贝,为了快速高效进行数据 EC 模式转换,我们改造了 distcp 的实现。
(3)、EC 文件检验和支持
Hadoop 2.6.0 版本中没有实现普通文件和 EC 文件的校验和验证方式,但是数据作为公司最重要的资产,我们在对普通文件转 EC 时,必须要进行转换文件的校验,以免 EC 后的数据存在问题。我们使用了社区中 HDFS-13056 实现的 COMPOSITE_CRC 方式来对 EC 模式文件和原文件进行校验和验证,从而来保证 EC 数据的正确性
(4)、EC 自动转换管理平台
我们开发了冷数据自动转换 EC 的管理平台,实现冷数据自动识别和自动执行转换为 EC 模式文件。
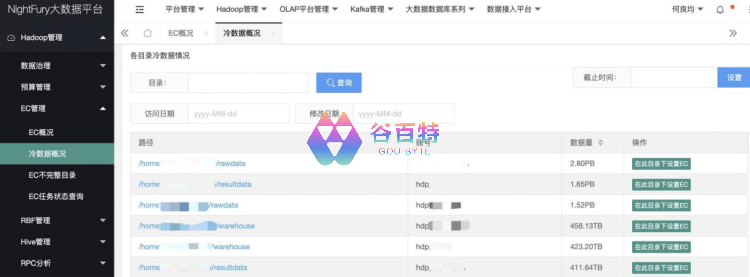 EC 落地效果:
EC 落地效果:
历史累计冷数据:50P,EC 转换后为 25P,节省存储空间 25P;
每季新增冷数据:5P,EC 转换后为 2.5P,每季度可节省存储空间 2.5P。
说明:我们冷数据定义为 1 年以上未访问的数据。
三 yarn的升级
由于是跨大版本升级,技术挑战大,存在很多未知风险,我们希望严格遵循以下几个原则来进行相关 Yarn 升级准备工作:
① 对业务完全透明:升级不影响用户现有任务,不影响用户提交新任务;
② 兼容所有计算框架:升级保证现有计算框架都能准确执行;
③ 支持滚动升级 / 降级:升级有问题,相关服务可以从 3.2.1 版本降级到 2.6.0 版本。
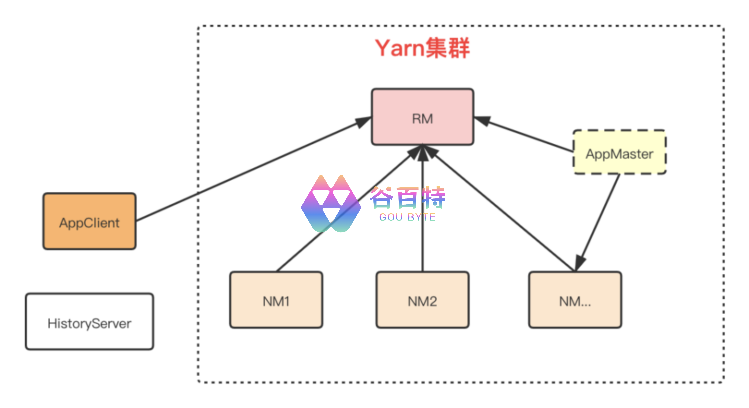
以下是 Yarn 组件的简单架构图:
1、升级梳理
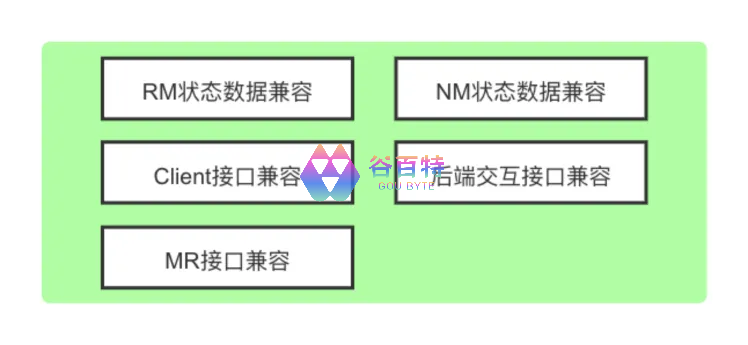
我们按以上 5 个方面对 Yarn 升级进行了梳理,保证 Yarn 升级工作的全面性和准确性。以降低升级风险。
①、RM 状态数据兼容
Yarn 本身有一些状态数据,比如 app 及其相关的 attempt 信息、token 信息、标签和 container 等信息,状态信息 RM 端是存储到 ZK 中的,NM 是存储到本地的 LevelDB 中的,我们升级时要求做到能升级还能降级,所以升级时旧版本状态能否被新版本 RM/NM 准确识别,降级时新版本 RM/NM 生成的状态能否被旧版本 RM/NM 准确识别就至关重要了。Yarn 的状态数据兼容要考虑两个方面:数据结构,存储方式(组织方式)。
梳理 RM 状态对应的协议发现,3.2.1 新增了很多信息,但是在 ProtocolBuffer 层面都做了兼容。但是 RM 状态在 ZK 中的存储方式发生了变化,3.x 版本中 app 和 token 状态信息在 ZK 中使用了更深节点层级关系来存储,社区对应 issue 为 YARN-2962 和 YARN-7262,为了向前兼容,需要设置参数 yarn.resourcemanager.zk-appid-node.split-index 和 yarn.resourcemanager.zk-delegation-token-node.split-index 为 0 来关闭该功能,好在这两个参数默认值都为 0,不需要特殊设置。
② NM 状态数据兼容
NM 中的状态数据以 ProtocolBuffer 的形式存储到本地的 LevelDB 中的,3.2.1 新增了很多信息,但是在 ProtocolBuffer 层面也做了兼容。不过由于 3.2.1 版本 NM 新增的状态信息,在回滚到 2.6.0 时会出现 NM 不识别的 key,报错如下:
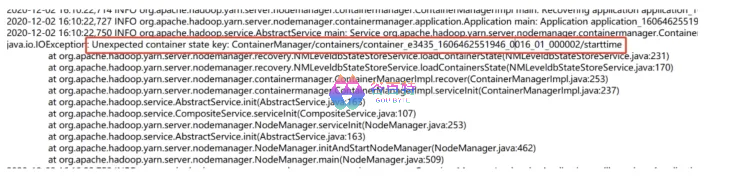
这部分需要从代码层面做一下兼容,我们修改代码将 3.2.1 NM 新增的状态信息不保存到 LevelDB 中,并通过开关控制,这样就避免了该问题,待 NM 都滚动升级到 3.2.1 版本并稳定后,再打开开关保存新增状态。
③ Client 接口兼容
考虑到客户端的复杂性,升级 Yarn 时,我们也只会升级 Yarn 的服务端,客户端还是保留为 2.6.0 版本。所以需要保证 2.6.0 的客户端可以正常访问 3.2.1 的 Yarn 后端服务。经过梳理和测试,2.6.0 版本的客户端访问 3.2.1 版本的 Yarn 服务端是完全兼容的。
④ 后端交互接口兼容
在升级过程中存在新旧 RM/ 新旧 NM 等中间状态,这就要保证新旧版本服务之间接口兼容。经过测试,后端服务的交互接口都是兼容的。不过 2.8.0 版本中 NM 新增了一个注销接口,在停止 NM 进程时,会导致 NM 本地的任务也被停掉,该功能是在 YARN-41 引入的,需要通过配置 yarn.nodemanager.recovery.enabled=true 和 yarn.nodemanager.recovery.supervised=true 来避免触发 NM 的停止注销。
同时从 2.8.0 版本开始,CGroup 在计算 NM 可用内核数时,默认计算的是物理核数,而非按超线程数计算,出现可用核数偏少,导致任务执行时不能充分利用 CPU 资源,任务执行会变慢,对应为 YARN-160,需要将参数 yarn.nodemanager.resource.count-logical-processors-as-cores 设置为 true,这样才能按逻辑内核计算,也就是按超线程来计算 NM 可用内核数。
同时从 YARN-668 开始,Yarn 相关 Token 的序列化反序列化开始支持 ProtocolBuffer,NM 从 2.6.0 滚动升级到 3.2.1 过程中,会出现兼容性问题,需要回滚该 issue 的修改,才能保持兼容。
⑤ MR 接口兼容
梳理了 MR 相关的接口,大部分都是兼容的,但是 TaskUmbilicalProtocol 协议接口存在兼容性问题,该接口是 Map/Reduce 子任务和 MRAppMaster 进程的通信接口,该通信接口的协议基于 Writable 实现,在滚动升级 NM 期间,MR 的任务在 3.2.1 版本和 2.6.0 版本之间通信时存在兼容性问题。如果从服务端做兼容需要进行一次集群升级,而且存在不可控风险,我们最终通过修改 Hadoop 2.6.0 客户端来保证 MR 任务 classpath 在集群中的一致性来解决该问题。
对应 fad9d7e85b1ba0934ab592daa9d3c9550b2bb501 提交和 YARN-41 中,RM 新增了两种 NM 状态:NS_DECOMMISSIONING/NS_SHUTDOWN,用于维护 NM 的下线和停止注销状态,这两个状态在 RM 和 MR 的 MRAppMaster 心跳交互时会下发到 MRAppMaster 端,之前为了解决 NM 滚动升级期间 MR 接口兼容问题,我们的 MR 任务在 NM 上用的都是 2.6.0 版本的 jar 包,导致 NM 新增的两种状态不能被识别,如果 NM 出现下线和停止注销的情况,MR 任务的 MRAppMaster 会出现空指针异常并进行任务重试,导致任务重新调度,为了解决这个问题,我们修改了 RM 端代码,暂时不下发这两种新增的 NM 状态信息。
2、代码整合
在 Hadoop 2.6.0 版本中,我们针对 Yarn 进行了很多的优化和改进,包括公平调度的性能优化、公平调度支持标签、调度吞吐 CPS 指标、任务失败诊断、坏盘检查、任务优先级等,我们将这些重要 patch 迁移到了 3.2.1 版本。
3、测试
Yarn 跨大版本升级存在较大的难度和风险性,虽然进行了全面的梳理,但是也需要进行尽可能全面的测试,测试内容包括:
① 计算框架测试:在客户端为 2.6.0 版本,Yarn 服务端为 3.2.1 版本情况下,MR/Hive/Spark/Flink,经过测试都是可以正常执行的。
② 自研框架测试:我们对公司其他团队自研计算框架也进行了兼容测试,发现存在一些问题,大都在 Yarn 侧修改兼容,部分需要业务侧调整的,也推进业务进行了调整。
③ 滚动升级测试:由于我们是从 2.6.0 版本滚动升级到 3.2.1,NM 节点会同时存在两个不同的版本,所以需要重点测试 NM 滚动升级过程中各个计算框架的兼容性。经过测试发现 MR/Hive/Spark/Flink 都可以正常执行。
④ 调度性能测试:RM 的调度性能至关重要,我们将 2.6.0 版本中的多个调度性能优化点迁移到了 3.2.1 版本,保证了 3.2.1 版本 RM 的调度性能不会低于 2.6.0 版本的性能。并经过压测后发现调度性能相比 2.6.0 有比较大的提升。
4、上线
我们的 Yarn 集群升级也分为成了两个阶段:
① 主节点升级阶段:
我们先将 3 个离线集群的 RM 升级到了 3.2.1,到目前已经稳定运行了一段时间。
② NM 升级阶段:
目前已经将其中一个近千个节点 Yarn 集群的 NM 升级到了 3.2.1,其他集群正在灰度中。
四 MR3升级
MR 在 3.x 版本有很多重大的改进,比如 NativeTask,FileOutputCommitter 优化等,可以有效提升 MR 的执行性能。但我们发现要直接使用 MR3 也存在一些问题。
1、NativeTask不支持Hive任务的序列号/反序列化
由于历史原因,我们集群中很大一部分还是 Hive 任务,为了利用上 MR3 的 NativeTask 特性,NativeTask 需要支持 Hive 的序列号 / 反序列化,为此我们自定义了 HivePlatform 类来支持,并且修改了相关的本地库代码。
2、MR3透明升级
为了可以及时利用上 MR3 的各种重大特性和改进,我们希望在 Yarn 服务端没有完全升级到 3.2.1 版本的情况下也能用上线 MR3,基于这个想法,我们采用了和前面滚动升级 NM 期间 MR 解决兼容类似的解决方案,在 Hadoop 2.6.0 客户端实现将 MR3 相关的 jar 包作为 classpath 在 NM 中执行,同时将 NativeTask 中的本地库以分布式缓存方式传递到 NM 端来实现 MR3 启用 NativeTask 特性。
通过我们测试对比,基于 MR3(开启 NativeTask)Hive SQL,平均性能比基于 MR2 提升了 15% 以上。
五 展望未来
在完成 HDFS 架构升级到 3.2.1 后,我们已经成功落地了 RBF 和 EC,并且取得了很好的效果,今年在逐步完成 Yarn 架构升级后,我们将基于 HDFS 的内核改造和 Yarn 的 Federation 特性来落地 Hadoop 单集群的跨机房部署,我们也将在未来一段时间逐步开启 Hadoop 3.x 版本 HDFS 和 Yarn 的更多重大特性,享受 Hadoop 架构升级带来的好处,为公司各业务部门提供更加高效的离线数据存储和资源调度平台,达到降本增效的目标。
作者简介:
良均,鹤铭,丹琦,家成,数据平台部 Hadoop 方向研发工程师。
评论区