
谷百特博客
温度 IT 记忆,传播IT和软件技术的博客
目 录CONTENT

以下是
大数据
相关的文章
-

-
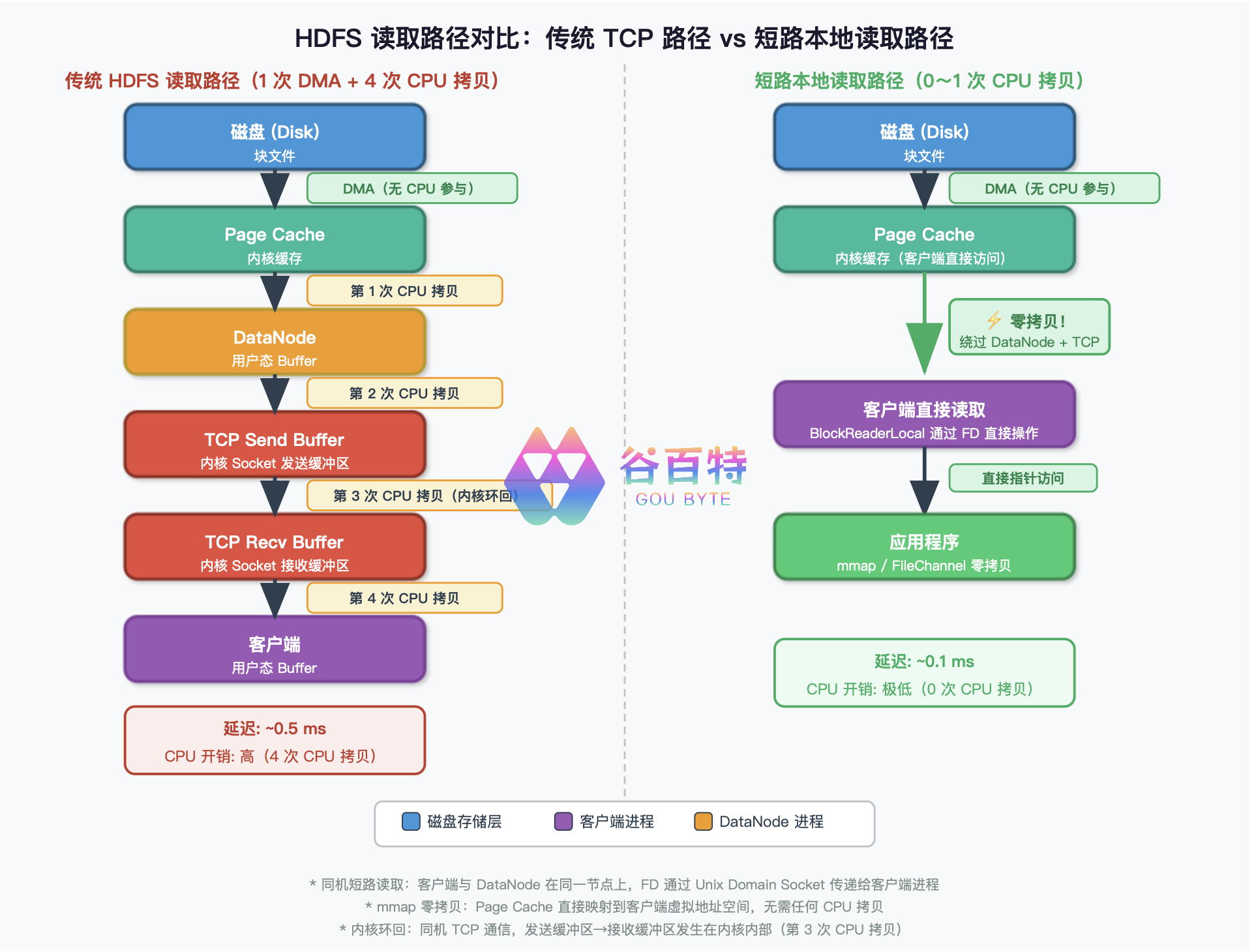
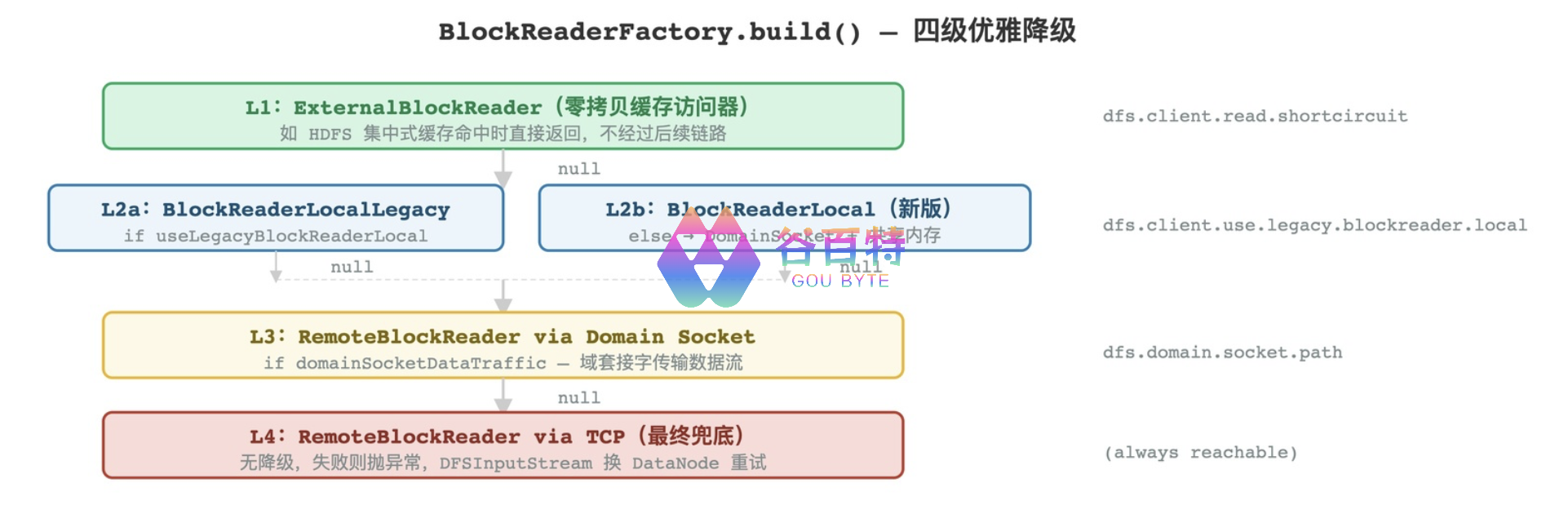
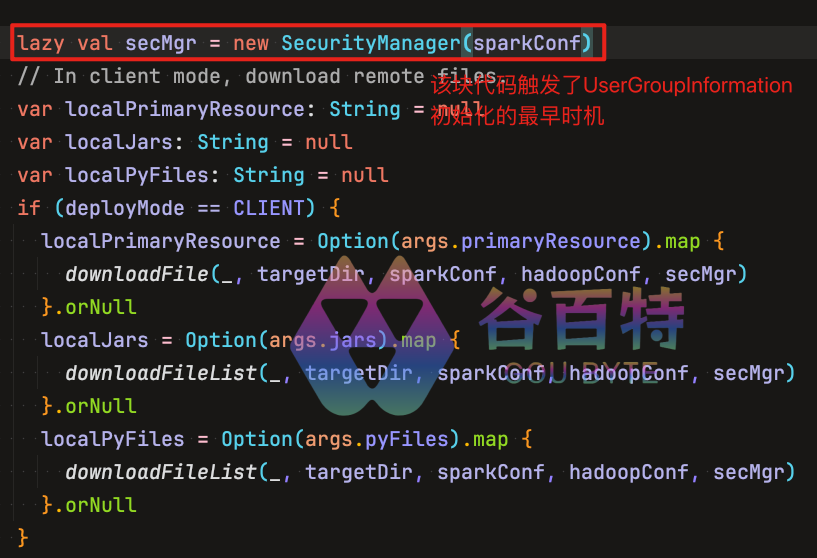
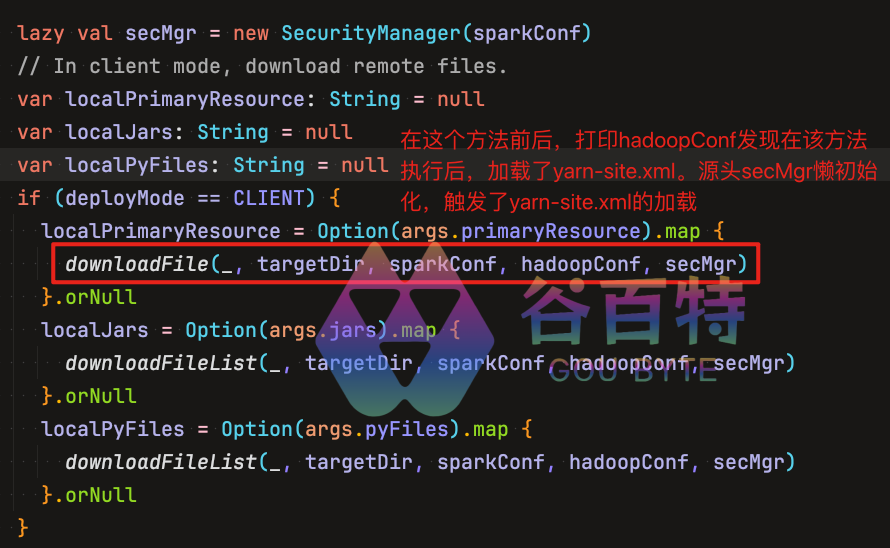
HDFS 短路本地读取系列(二):你以为的「本地读」和真正的「本地读」—getLegacy vs getBlockReaderLocal 的本质差异 在 HDFS 的读取路径中,BlockReaderFactory.build() 是客户端选择读取策略的总入口。在这个四级降级链路中,第二级和第三级分别由 getLegacyBlockReaderLocal() 和 getBlockReaderLocal() 接管。一个基于文件路径直接打开(HDFS-2246),一个基于 Unix Domain Socket 文件描述符传递(HDFS-347)。本文将深入 Hadoop 3.x源码,彻底解读这两个方法的内部机制、调用链路与设计哲学。
-
-
-
-