

一、我们为什么要升级
360 之前 YARN 版本是基于 2.7 版本修改的内部版本,主要有几个问题:
与社区脱节:目前社区已经发展到 3.2 的版本,落后社区多个大版本,很多新特性都不能使用,比如预定系统,Opportunistic Containers 等
降本增效:在 Yarn 层面,支持多集群 Federation,可以有效利用多 YARN 集群空闲资源,达到降本增效的目标。
定制化功能太多:由于 YARN 在我司发展时间比较长,有很多定制化的功能
调度性能瓶颈
二、挑战和目标
挑战
版本跨度大:版本从 2.7 到 3.2,版本跨度比较大
客户端包多:mr,hive,hbase,flink,spark,hbox 等作业都调度在 YARN 上
用户复杂度比较高:YARN 的集群服务于 360 公司所有业务线如 360 搜索,手机卫士,360 金融等
作业问题:classpath 和配置依赖;MR,hive,ditcp 作业高低版本共存导致作业失败,hbox 作业接口不兼容,用户自己上传 jar 包
历史包袱:集群中还有很多 corona 用户,所以要兼容 conrona 参数、一些自定义的功能
集群环境复杂:系统版本,python 版本,php 版本,LANG 编码问题等
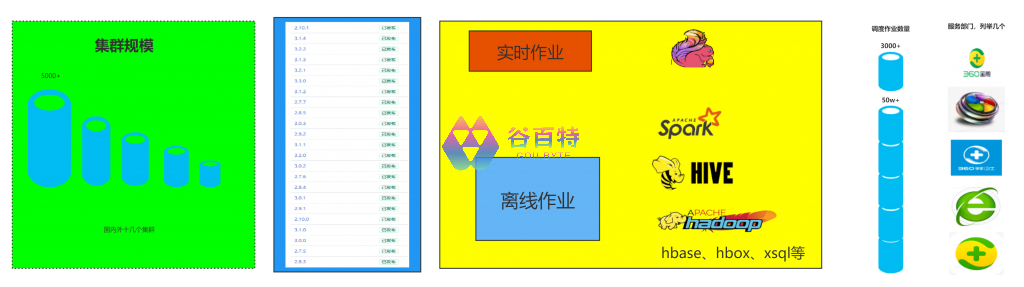
图 1- YARN 升级面临的挑战
目标
对于业务完全透明,不影响现在正在跑的作业,同时不影响用户提交新的作业
兼容 mr,hive,hbase,flink,spark 等计算框架
支持滚动升级 / 回滚,让服务能够在 3.2 和 2.7 之间无差别回滚
YARN 的简单架构如下图所示
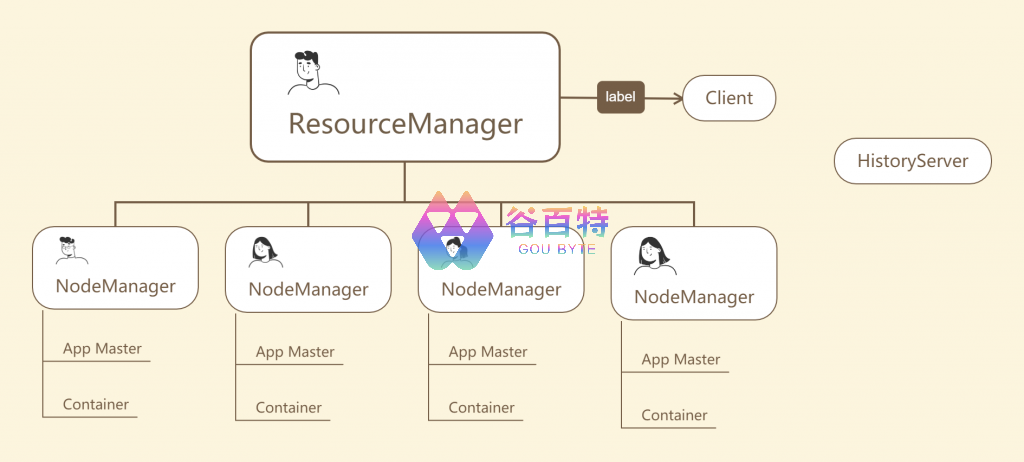
图 2- YARN 架构
三、升级梳理
重点功能梳理
我们前期从下图对 YARN 进行了重点功能的梳理,涉及 134 个功能,371 个 patch,进而来保证 YARN 升级工作的全面性和准确性,进而降低升级的风险,熟悉代码,预备升级出现的突发故障。
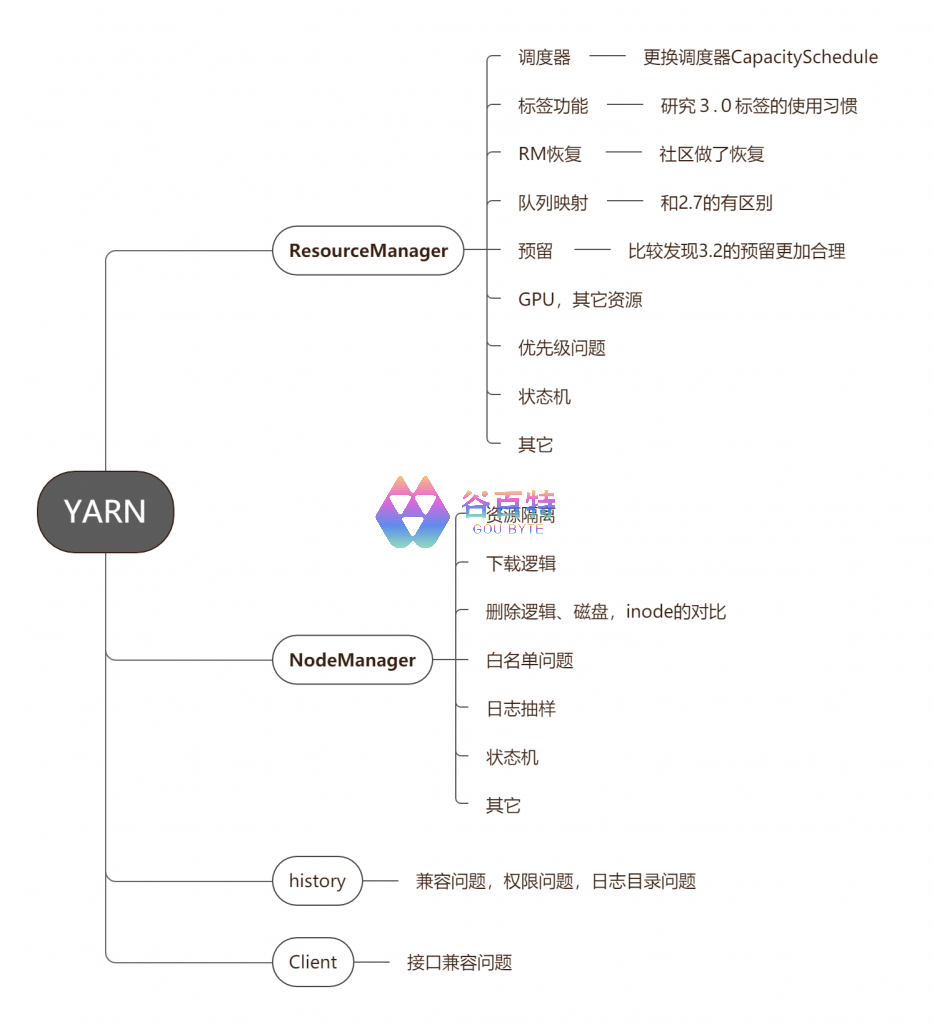
图 3- YARN 重点功能梳理
升级测试
测试主要过程

图 4- YARN 升级测试步骤
测试框架梳理
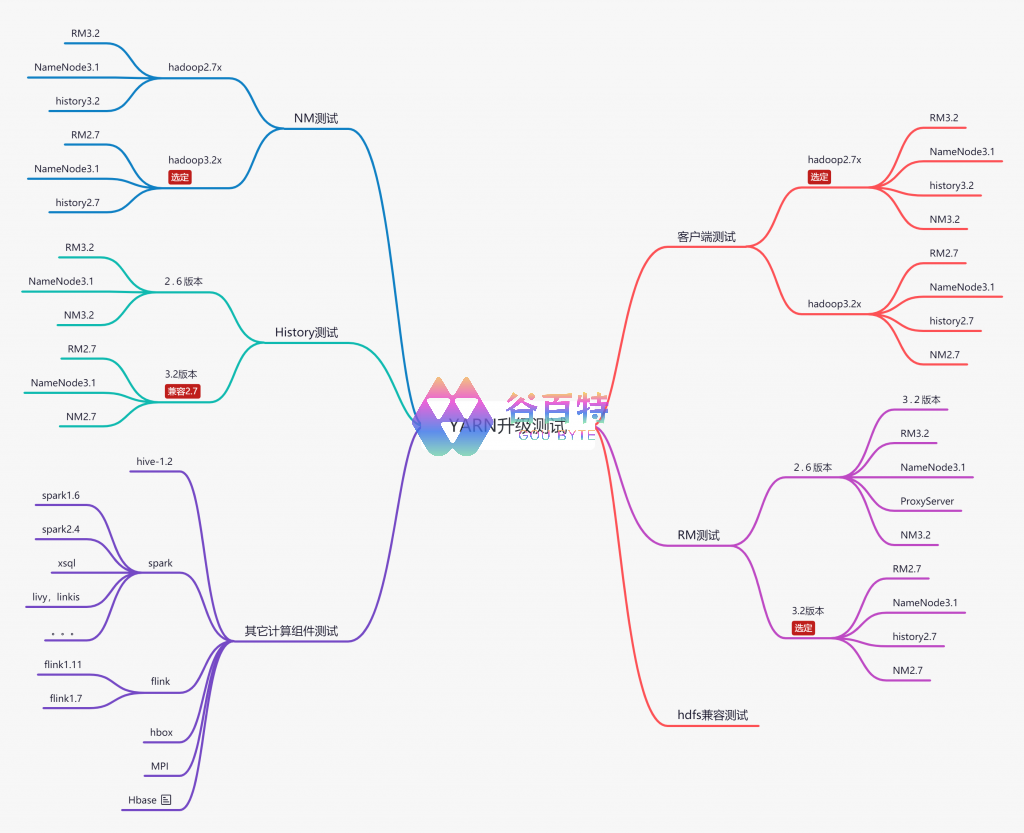
图 5- YARN 升级测试设计
主要功能测试
ResourceManager
重点功能梳理和测试,例如 CapacitySchedule
调度器的使用:2.7.2 的 yarn 使用的是 FairScheduler,社区目前主要方向都在 CapacityScheduler 。
我们也对 CapacitySchedule 重点功能做了梳理和针对性测试
表 1- Cap 和 Fair 重点功能对比
重点功能测试后续修改和注意
为了平滑使用新的调度器,针对我们的梳理的结果和我司使用调度器的一些习惯,我们做了以下工作:
自动化转换脚本:写了队列转换脚本,可以一键让 FairScheduler 转换成 CapacityScheduler
标签调度问题:①:兼容问题:2.7x 的 label 是我司自己加的,我们对此 3.0 做了平滑升级的兼容工作。
②:独占和非独占之间转换的问题:比如 YARN3.0 的调度器不支持把独占标签改成非独占,2.7 的 DEFAULT_LABEL 和 3.2 的空标签等
③:标签堵塞:指定标签的时候容易触发
* 队列映射:2.7如果用户不指定队列就会提到default队列,但是3.0如果不指定,%user:%user没有的话就会作业就会提交失败
回滚测试:升级可以平滑从 2.7 升到 3.2,也可以从 3.2 升到 2.7,社区自己做了处理
CapacityScheduler 新增限制:用户 AM 限制和 userLimit 的限制,最大资源限制的计算,我们对这块都做了修改
resultful 接口展示的数据问题
GPU 等其它资源计算存在问题
队列最大资源保证:我司的情况是默认标签一般是空标签,它可以使用非独占标签的资源,对于集群比较紧张的队列,队列最大资源保障就不合理
RM 日志过大
ResourceManager 回归测试
性能测试
用 SSL 对 FairScheduler 和 CapacityScheduler 做了性能测试。
测试用例:
①:不开多线程 + 开 multAsigned
②:测试用例多线程 + 线程数 5
③: 不开多线程 + 不开多次分配
测试结果:
①:不开多线程调度, Hadoop3.2 capacity 调度 container 的吞吐能力 要比 hadoop2.7-fair scahduler 要好
②:开多线程调度, Hadoop3.2 capacity 调度 container 的吞吐能力 要比 hadoop2.7-fair scahduler 要好
NM 的测试
①:支持灰度升级(升级测试的时候就按照 5%,10%,50%,100%)
②:升级可以平滑从 2.7 升到 3.2,也可以从 3.2 降到 2.7,修改了 2.7recover 逻辑
③:我司加的一些旧功能:使用客户端的配置下载资源、动态控制作业并发、inode 清理等功能合并到 NM3.0 上
④:NM 压测
客户端测试
客户端这次保持版本 2.7x,原因如下
①:由于 TaskUmbilicalProtocol 协议接口存在兼容性问题,该接口是 Map/Reduce 子任务和 MRAppMaster 进程的通信接口,该通信接口的协议基于 Writable 实现,在滚动升级 NM 期间,MR 的任务在 3.2.1 版本和 27.x 版本之间通信时存在兼容性问题。如果从服务端做兼容需要进行一次集群升级,而且存在不可控风险,我们最终通过修改 Hadoop 2.7.x 客户端来保证 MR 任务 classpath 在集群中的一致性来解决该问题。
②:hive 作业在我们占的比重也比较大,因为我司的 hive 还在 1.2 的版本,不支持 hadoop3.x,spark sql 又会访问 hive 的 metastore
各大计算框架测试
①:建立升级测试用例库(ps:感谢各大计算组建的支持和配合)
②:在上图 2- YARN 升级测试设计集群环境下分别测试
四、升级方案
升级架构
集群选择的升级架构如下图所示,客户端为低版本,集群版本为高版本
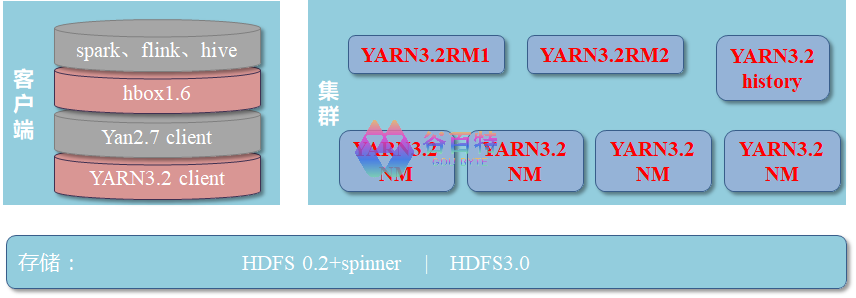
图 6- YARN 升级测试设计
升级步骤
升级方案经历过我们团队反复实验和验证,得到以下比较合理的升级方案:

图 7- YARN 升级步骤
详细步骤:
升级前都会按照线上集群搭建测试集群,跑我们准备的测试脚本
升级前准备好:集群队列监控,集群资源监控,重点作业监控,对 2.7 和 3.2 的接口做好测试,备份日志,对每分钟 Failed 作业加报警
升级客户端配置
备份 Hadoop2.7 的标签到临时目录
升级 Hadoop3.2 的 ResourceManager,同时保存 Hadoop2.7,在升级出现问题的时候可以马上切回 2.7
升级 hadoop3.2history,兼容 2.7 的 history
观察集群一周(根据升级集群数量决定,我们升级第一个集群等待时间比较长),同时观察集群 container 的吞吐率和作业运行快慢。
在升级 RM 的一周内,同时建立一个测试标签,让重点用户可以测试,可以发现一些我们在测试用例库中没有测试到的地方
升级计算节点,我们是灰度升级 NM。
按照 5%->10%->30%->70%->100% 对 NM
升级的时候按照标签升,如果确实有作业在 3.0 上确实有问题,但是问题涉及用户数不多,这个时候 可以让用户指定没有升级的标签跑,这样可以给开发人员预留一些时间去排查问题
升级完成之后观察集群,统计集群升级前后的效率
五、升级遇到的问题和解决
1. ResourceManager 升级遇到的问题
ResourceManager 由两个关键组件 Scheduler 和 ApplicationsManager 组成。这次升级主要是把调度器 FairScheduler 转换到 CapacityScheduler,平滑过度,需要考虑的一些比较主要的问题
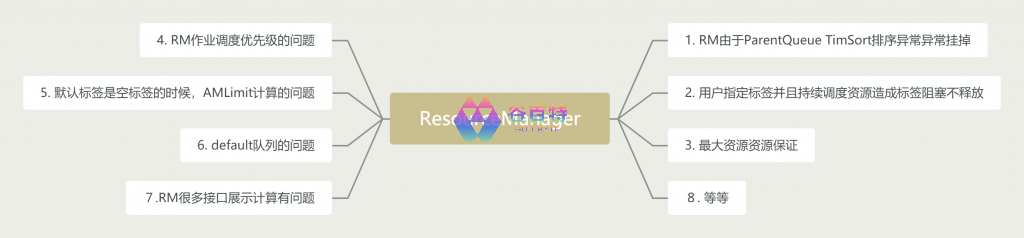
图 8- ResourceManager 升级
问题1:RM 由于 ParentQueue TimSort 排序异常异常挂掉
具体报错
java.lang.IllegalArgumentException: Comparison method violates its general contract!问题解决
①:社区目前还没有出解决思路,不过可以参考 patch:YARN-8737 和 YARN-10058
②:目前的解决方案:-Djava.util.Arrays.useLegacyMergeSort=true 把这个参数加在 RM 的启动参数,测试了一些性能,对 RM 性能没有产生比较大的影响,所以我们先用此方案解决
问题 2:用户指定标签并且持续调度资源造成标签堵塞问题
具体表现
夜间标签调度资源的时候就会一直优先给指定标签的,该标签下其它队列调度不到,资源闲置
问题解决
修改代码逻辑,用户指定标签跳出选择队列的逻辑,具体的 patch 整里好会提交到社区
问题 3:最大资源资源保证
具体表现
CapacityScheduler 最大资源控制和 FairScheduler 最大资源控制不一样,造成高峰期资源紧张。
原因:CapacityScheduler 的最大资源保证分为:
①:在进行 RESPECTPARTITIONEXCLUSIVITY 分配时,我们将尊重队列的最大容量。
②:在进行 IGNOREPARTITIONEXCLUSIVITY 分配时,我们将不遵守队列的最大容量,该分区上队列的最大容量将被视为 100%。哪个队列可以使用分区中的所有资源。
设计的缺点
对于集群资源比较紧张的集群就会出现重要作业的资源被抢占,任务不能正常跑出来
设计的优点
对于非排他性分配,我们确保分区上有空闲资源,以避免浪费,这种资源将得到最大程度的利用,抢占策略将在 partitoned-resource-request 返回时将其取回
问题解决
修改代码逻辑,增加队列最大资源上限的控制,同时增加开关,对于资源不紧张的集群可以放开,这样可以增加集群的资源利用率。
问题 4:RM 作业调度优先级的问题
具体表现
如果不配,集群最大 priority 默认是 0,用户作业指定优先级无效
问题解决
<property>
<name>yarn.cluster.max‐application‐priority</name>
<value>5</value>
</property>2. NM 升级遇到的问题
NodeManager 管理 YARN 集群中的每个节点。NodeManager 提供针对集群中的每个节点的服务,从监督一个容器的一生和节点健康,在升级的时候,遇到下面几个需要提前注意的的问题
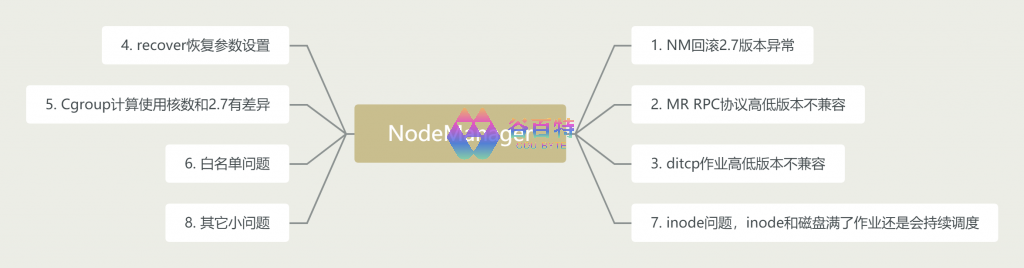
图 9- ResourceManager 升级
问题 1:NM 回滚 2.7 版本异常
具体报错
NM 中的状态数据以 ProtocolBuffer 的形式存储到本地的 LevelDB 中的,3.2.1 新增了很多信息,但是在 ProtocolBuffer 层面也做了兼容。不过由于 3.2.1 版本 NM 新增的状态信息,在回滚到 2.7.x 时会出现 NM 不识别的 key
问题解决
方案一:修改 hadoop2.7 的代码,让它增加 3.2.1 版本 NM 新增的状态信息,升级 hadoop2.7.x
方案二:修改 hadoop2.7 的代码,使 3.2.1 版本 NM 新增的状态信息加开关先关闭,等 NM 全部升级完在打开
我们选择了方案一,一是尽量不再 3.2 的代码上反复的修改,二我们使用的是我们经过大量的测试和灰度升级,出现问题解决不了必须要回滚的概率尽量已经控制到最低
问题 2:MR RPC 协议修改导致作业执行异常
具体报错
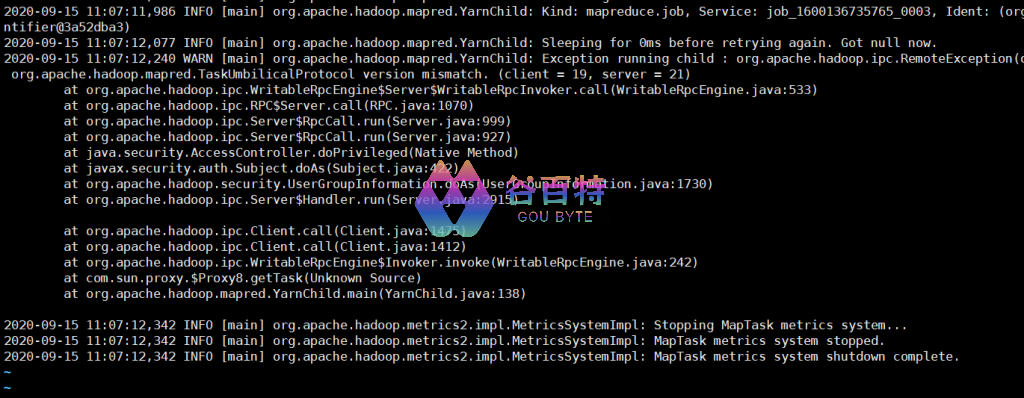
图 9- RPC 协议修改导致作业执行异常
问题解决
在客户端控制 MR 单个作业的 class path 保持一致
问题 3:distcp 作业在 2.7 和 3.2 版本报错
ditcp 必须要保持版一致
具体报错
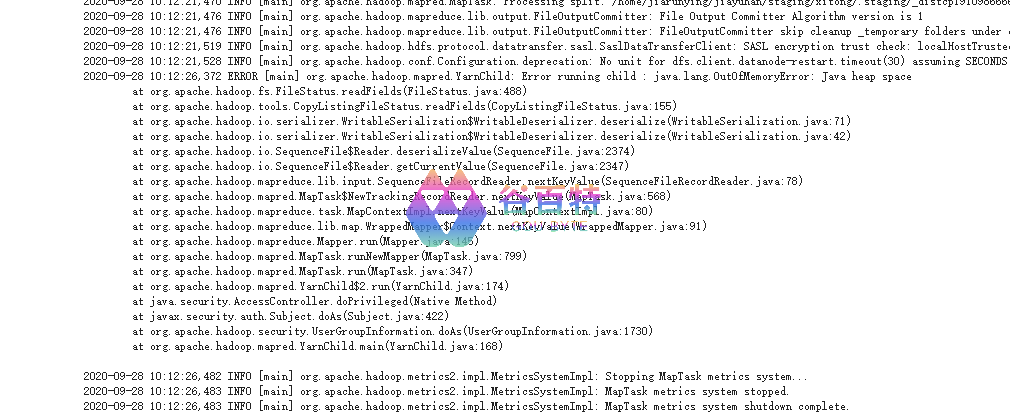
图 10- RPC 协议修改导致作业执行异常
问题解决
和 mr 的解决办法一样客户端控制 ditcp 单个作业的 class path 保持一致
问题 4:recover 恢复异常
具体原因
新版本的 recvoer 在 NM 注销的时候多加了一个参数,默认 yarn.nodemanager.recovery.supervised=false,NM 停止注销的同时,NM 本地的进程任务也被停掉,recover 恢复失败
问题解决
在升级的时候需要增加参数
<property>
<name>yarn.nodemanager.recovery.supervised</name>
<value>true<value>
</property>问题 5:Cgroup 计算 NM 核数和 2.7 有区别,会造成作业变慢
具体原因
NM 会按照机器总的 CPU num* limit-percent 来计算 NM 总体可用的实际 CPU 资源,然后根据 NM 配置的 Vcore 数量来计算每个 Vcore 对应的实际 CPU 资源,再乘以 container 申请的 Vcore 数量计算 container 的实际可用的 CPU 资源。这里需要注意的是,在计算总体可用的 CPU 核数时,NM 默认使用的实际的物理核数,而一个物理核通常会对应多个逻辑核(单核多线程),而且我们默认的 CPU 核数通常都是逻辑核
问题解决
修改配置
<property>
<name>yarn.nodemanager.resource.count-logical-processors-as-cores</name>
<value>true<value>
</property>3. history 升级遇到的问题
具体问题
升级之后 history log 路径问题,会让我们在滚动升级中看不到日志
问题解决
在 3.0 的基础上做了兼容,加了开关,等全部升上去之后再把开关置成 false
六:升级的喜
Resource Manager 升级:
目前我司的大大小小的集群主节点基本都已经升级 YARN3.0,升级之后的调度调度效率比之前提升 30% 左右,资源利用率提高 15% 左右
NodeManager 升级阶段:
目前我们已经完成一个 4000 节点,一个 5000 节点集群的 NM 的升级,还有数 10 个小集群的升级
MR 更快的执行速度,shuffle 类的作业,性能大概提升 15% 到 30%
跟进社区新版本,新功能可以陆陆续续投入使用
评论区