

HBase 是 Pinterest 最关键的存储后端之一,为我们的许多在线流量存储服务提供支持,如 Zen (图形数据库) 和 UMS (宽列数据存储)。尽管 HBase 具有许多优势,例如在高容量请求中的行级别的强一致性,灵活的模式,对数据的低延迟访问以及 Hadoop 集成,但它本身并不支持高级索引和查询。辅助索引是我们客户最需要的功能之一,但直接在 HBase 中支持它是相当具有挑战性的。随着索引数量的增长,维护单独的索引表在查询效率和代码复杂性方面不是可扩展的解决方案。这促使我们构建了一个名为 Ixia 的存储解决方案,它在 HBase 上提供了近乎实时的二级索引。设计灵感主要来自百合 HBase 索引器。
Ixia 在 HBase 之上提供了一个通用的搜索接口,它扮演了真实来源数据库的角色。搜索引擎针对倒排索引查找进行了本机优化,存储索引。搜索引擎还提供了一组丰富的搜索和聚合查询,并支持 Pinterest 的大多数索引和检索用例。
在这篇文章中,我们将首先简要介绍系统的架构和设计选择。然后,我们将介绍如何维护 Ixia 的数据一致性 SLA,如何解决灾难恢复问题,以及我们必须采取哪些措施来提高整体系统性能。最后,我们将提供一些关于未来工作和机会的指导方针。
体系结构
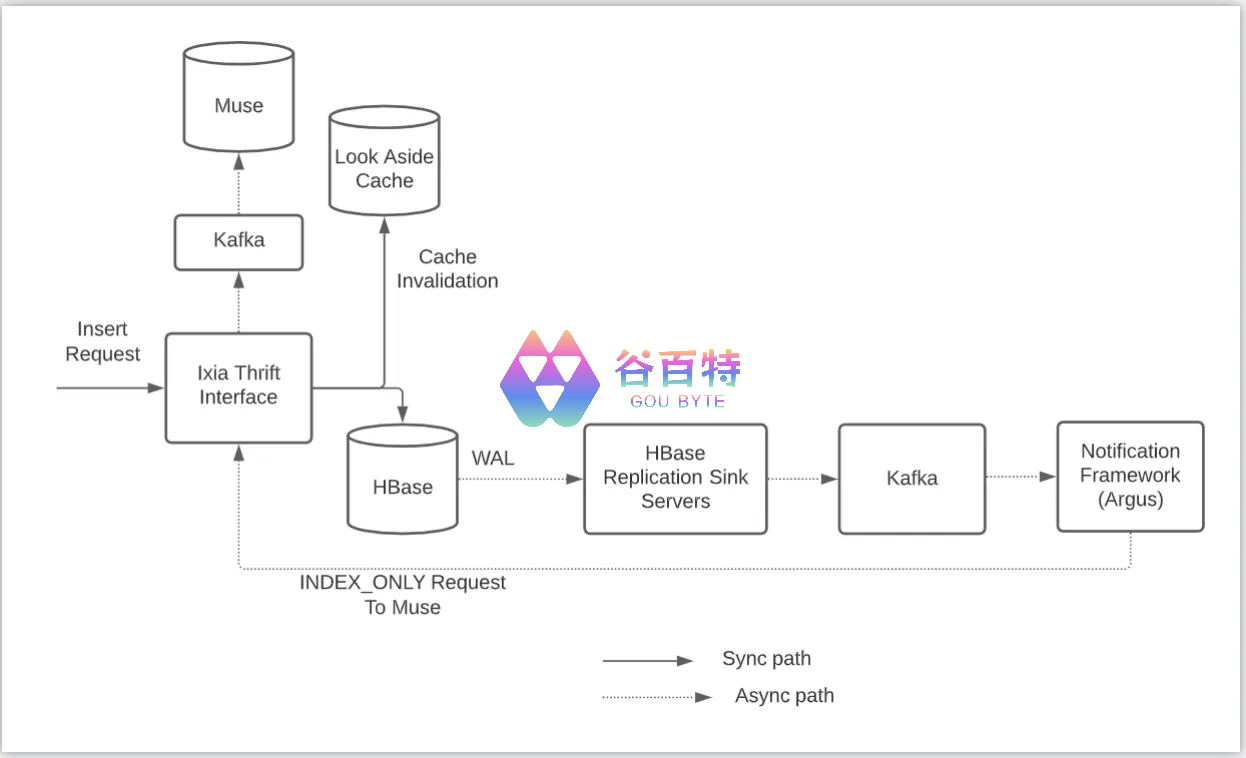
图 1: 显示数据流的系统架构
在小节中,我们将简要描述每个组件,以最终解释整个流程。
HBase
HBase 是一个面向列的 NoSQL 数据库管理系统,运行在 Hadoop 分布式文件系统 (HDFS) 之上。它以 Google 的大表为模型,用 Java 编写。它非常适合实时数据处理或对大量数据的随机读 / 写访问。我们使用 HBase 作为 Ixia 的真实来源 DB。
复制机制和变更数据捕获 (CDC) 系统
HBase 复制是一种将数据从一个 HBase 集群 (主集群) 复制到另一个集群 (辅助集群) 的机制。这是通过将提前写入日志 (WAL) 中的提前写入日志条目 (WALEdits) 从活动群集重播到备用群集区域服务器来异步完成的。WALEdit 是表示一个事务的对象,并且可以具有多个突变操作。由于 HBase 支持单行级事务,因此一个 WALEdit 只能有一行的条目。
我们引入了实现备用集群的复制接收器 api 的自定义 HBase 复制接收器服务器。replication sink 服务提供业务逻辑,将 WAL 事件转换为消息,并在不更改 HBase 代码的情况下将其异步发布到 Kafka。如果复制接收器服务器能够将此事件发布到 Kafka,则复制接收器服务器向复制源 (主) 集群发送确认 (ACK)。
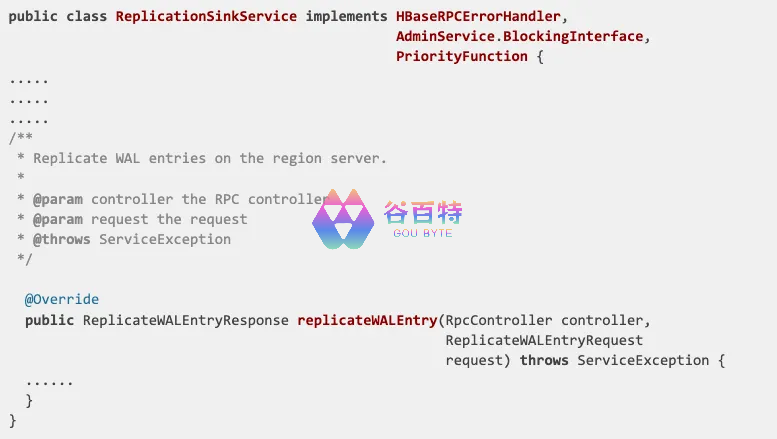
图 2: 显示复制接收器服务的 API 的代码段
内部通知框架 Argus 接收 Kafka 事件,并根据事件触发业务逻辑。
这两个系统与 Kafka 一起构成了我们基于 HBase 的 CDC 框架的主干,除了 Ixia 之外,该框架还广泛用于多个用例。HBase 复制接收器机制保证所有 wal 都发布到 Kafka,其消费者为每个事件执行客户定义的业务逻辑。
搜索引擎
我们有一个内部搜索引擎缪人, 这是一个通用的信息检索平台。Muse 针对在线服务进行了大量优化,并提供了一组丰富的搜索和聚合查询。Muse 在 Pinterest 上用于不同的关键用例,如 home feed,广告,购物等。ixia 使用 Muse 作为其搜索引擎,在非行键列中提供丰富的搜索功能。
我们评估了 Solr 或 ElasticSearch 作为搜索引擎。两者都具有广泛的行业采用以及良好的查询和索引性能。Muse 具有与 Solr 和 Elasticsearch 等效的功能,并且完全集成在 Pinterest 堆栈中。我们决定选择 Muse,以使技术堆栈与 Pinterest 的其余部分保持一致。尽管如此,Ixia 中的可插拔查询引擎接口使将来可以更轻松地切换到其他搜索引擎。
高速缓存
Ixia 使用 Pinterest 的分布式缓存基础设施由Memcached和Mcrouter。它使用一种后备缓存策略来优化读取性能并减少 HBase 上的负载。Ixia 的请求模式的特点是非常高的读写比 (约 15:1),并且添加缓存可以节省巨大的基础架构成本。每个缓存条目对应一个 ixia 文档,而 ixia 文档又对应一个 HBase 行。首先在缓存中同步检查读取请求并将其返回到客户端 (如果可用),并且从真实来源存储中异步回填缺少的条目。首先在缓存中删除所有写请求,以维护 Ixia 的数据一致性合同。Ixia 中的查询 API 提供了从文档中请求字段子集的灵活性。为了降低从缓存和 HBase 组装文档的实现复杂性,我们决定故意拒绝不包含所有请求字段的缓存条目,并在缓存中异步回填它们。
我们使用直写缓存策略进行了实验,发现如果 Ixia 在写入时间内写入缓存,则命中率非常低。由于高读 / 写比率,写流量非常低,以至于文档最终从 HBase 读取,并且缓存不是很有用。在如上所述将策略更改为后备策略之后,缓存命中率显着提高,并且已经达到 90% 左右。
端到端请求流
当一个 insert/upsert 请求进入时,Ixia 从缓存中删除这个键,并同步写入 HBase (如图 1 所示)。在被复制到复制接收器服务器之后,WAL 被发布到 Kafka。通知框架 (Argus) 使用更新事件并发送向 Ixia 请求一个标志,指示服务仅通过 Kafka 更新 Muse。该流程对于删除 / 移除请求是类似的。
当查询请求进入时,Ixia 将其发送到 Muse 进行倒排索引查找。Ixia 然后在 HBase 中执行由 Muse 返回的所有 doc 键的正向数据查找,以确保 doc 存在于 truth 数据库的源中。
当 Get 请求进入时,Ixia 直接从数据库获取结果并将其返回给客户端。此 RPC 是用于直接 KV 访问 HBase 的相对较薄的包装器。
数据模型
Ixia 是一个文档存储,由以下不同的逻辑组件组成 -
命名空间 -Ixia 的命名空间与 HBase 中的命名空间和 Muse 中的命名空间具有 1:1 映射。
文档键 - 此键唯一标识 Ixia 文档,并与 HBase 行键具有 1:1 映射。
表 -Ixia 表映射到 HBase 表。
字段 -Ixia 字段被构造为 <namespace >:< table >:< hbase_column_family >:< hbase_column_name>,其唯一地标识 HBase 单元和 Muse 索引字段。
模式管理和生存时间 (TTL) 支持
Ixia 支持在线模式更改。HBase 是无架构的,但 Muse 使用事先声明的类型化架构。目前,Ixia 支持添加新索引,对在线流量没有影响。这些索引需要部署在 Muse 配置和 Ixia thrift 层中。新的索引可以稍后由客户端为较旧的文档回填。
Ixia 支持 TTL,保证 Hbase TTL +/- cache TTL。如果文档在 HBase 中缓存并过期,可能会出现不一致的情况。因此,我们为对到期准确性更敏感的用例设置了较短的缓存 TTL。
一致性模型
Ixia 与 HBase 类似,支持强一致性的 Get 请求。只有在对数据库的写入请求成功后,才会更新索引。这是 CDC 框架的自然结果,因为保证将 WAL 事件发布到复制接收器服务,从而发布到 kafka。通知框架使用这些消息,并通过 Ixia 向 Muse 发送索引请求。这种保证是使用 CDC 层进行索引的核心设计动机之一。查询 API 用于从搜索引擎搜索文档。它提供了丰富的功能,如基于匹配,成员资格,范围等的过滤,以及基于总和,平均值,最大值,最小值等的聚合结果,如图 3 所示。由于架构的异步索引,查询 API 最终是一致的。文档写入时间和可搜索时间之间的 P99 延迟约为 1 秒。

图 3: Ixia 的查询请求示例
业绩
Ixia 已经投入生产一年多,为购物、广告、信任和安全等几个关键用例提供服务。由于组件的分布式特性,系统是可水平扩展的。API thrift 层和 Muse 具有基于 CPU 警报的自动缩放。我们有监控和警报,以确保在扩展需求开始影响其他组件的系统可用性和可靠性之前满足这些需求。我们能够根据客户的需求调整 thrift 层、缓存层、muse 层和 HBase 层的配置。这些参数通常由诸如 qp、延迟、吞吐量、查询模式要求等因素确定。我们根据用例的关键程度、数据量等部署了专用和共享集群。我们的一个生产集群正在以约 5 毫秒的 p99 请求延迟服务约 40k qps,响应大小为〜12KB,99.99% 可用性 SLA。整个系统的最大吞吐量在〜250k qps 处达到峰值。
灾难恢复
为了容错,Ixia 由两个 HBase 集群支持。主集群提供在线流量,并持续复制到备用集群。如果活动群集出现问题,我们有适当的机制来进行零停机故障转移,并在不影响可用性的情况下使备用处于活动状态。
此外,还有一些系统可以执行定期 HBase 快照和连续 WAL 备份。这两种机制一起工作为我们提供了真实来源数据的时间点恢复。
我们有 Map reduce 作业,可以基于 HBase 快照确定性地派生索引。此离线 Muse 索引可用于在任何点启动新的 Muse 集群,只要真实数据的源是完整的。
因此,如果有数据损坏,我们有能力恢复真实来源数据以及索引。
学习和未来的工作
系统复杂性
在这样一个复杂的分布式系统上学习、贡献和加入客户端是一个很好的经验。由于 HBase 原生不支持二级索引,异步索引管道有多个组件增加了操作负载。
Ixia thrift 层的 API 表面积很大,允许客户端有很大的灵活性来编写昂贵的查询。这使得我们必须在各个层设置系统限制,以防止由于查询模式更改而导致的级联故障。诊断和调试这样的复杂错误增加了维护成本。
最终一致性
当前架构无法支持当前模型中的强索引一致性。由于 API 层是通用的,具有可插拔存储和搜索后端,因此我们正在探索与 Ixia 一起使用的其他 NewSQL 数据库,这些数据库可以支持强一致性并降低异步索引管道的复杂性。
我们目前支持最终索引一致性,p99 延迟为几毫秒,SLA 为 99.5%。少量失败的索引更新会记录在磁盘上,并在以后使用内部管道尝试使用 pub-sub 系统将数据从磁盘移动到数据湖。我们运行定期脱机作业,从数据湖中读取这些失败的索引请求,并使用联机路径重试。
确认书
我们要感谢整个存储和缓存团队,尤其是 Kevin Lin 和 Lianghong Xu。我们还要感谢我们的搜索 Infra 团队,尤其是谢海滨。最后,我们要感谢所有客户的支持和反馈。
评论区