

第一步:环境准备(只需执行一次)
1 安装 Homebrew(如果尚未安装)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"2 安装 ffmpeg(音频提取必须)
brew install ffmpeg验证:
ffmpeg -version3 安装 Ollama 并拉取大模型
下载地址:https://ollama.com/download (选择 Apple Silicon 版)
安装完成后,拉取模型:
ollama pull qwen2.5:14b-instruct-q4_K_M验证:
ollama list

4 创建并激活虚拟环境
python3.11 -m venv /Users/dev/gitrepo/llm/ollama/venv
source /Users/dev/gitrepo/llm/ollama/venv/bin/activate5 安装所有 Python 依赖(核心一步)
pip install --upgrade pip
pip install faster-whisper scenedetect moviepy pillow ollama tqdm imageio imageio-ffmpeg opencv-python-headless预下载 Whisper large-v3-turbo 模型(避免运行时超时) 先激活环境:
执行下载(使用社区稳定镜像):
pip install huggingface_hub[cli]
hf download dropbox-dash/faster-whisper-large-v3-turbo下载完成后,模型自动存入 ~/.cache/huggingface/hub/models--dropbox-dash--faster-whisper-large-v3-turbo
后续运行脚本时 faster-whisper 会直接使用本地缓存,无需联网。
第二步:保存脚本
将以下代码保存为 /Users/dev/gitrepo/llm/ollama/video_to_article_m2.py:
import os
import subprocess
from pathlib import Path
from faster_whisper import WhisperModel
from scenedetect import detect, ContentDetector
import ollama
import time
from moviepy import VideoFileClip
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# ================== 配置区 ==================
VIDEO_PATH = "/Users/dev/Downloads/12.mp4" # ← 修改为您的视频路径
OUTPUT_DIR = "output_m2"
WHISPER_MODEL = "dropbox-dash/faster-whisper-large-v3-turbo"
LLM_MODEL = "qwen2.5:14b-instruct-q4_K_M"
MAX_KEYFRAMES = 12 # 最大关键帧数量
# =============================================
os.makedirs(OUTPUT_DIR, exist_ok=True)
def extract_audio(video_path, audio_path):
if not Path(video_path).is_file():
raise FileNotFoundError(f"视频文件不存在:{video_path}")
print("提取音频...")
if Path(audio_path).exists():
print(f"音频文件已存在,将覆盖:{audio_path}")
result = subprocess.run([
"ffmpeg", "-y", "-i", video_path, "-vn", "-acodec", "libmp3lame", "-q:a", "2", audio_path
], capture_output=True, text=True, check=False)
if result.returncode != 0:
print("FFmpeg 提取音频失败:")
print(result.stderr)
raise subprocess.CalledProcessError(result.returncode, result.args)
print("音频提取完成")
def transcribe(audio_path):
print(f"语音转文字({WHISPER_MODEL})...")
model = WhisperModel(WHISPER_MODEL, device="cpu", compute_type="int8")
segments, info = model.transcribe(audio_path, beam_size=5, language="zh")
transcript = "\n".join([f"[{s.start:.1f}s → {s.end:.1f}s] {s.text.strip()}" for s in segments])
return transcript
def process_keyframe_for_originality(raw_path, output_path):
try:
img = Image.open(raw_path).convert("RGB")
width, height = img.size
img = img.filter(ImageFilter.GaussianBlur(radius=1.0))
border_color = tuple(random.randint(80, 220) for _ in range(3))
bordered = Image.new("RGB", (width + 40, height + 40), border_color)
bordered.paste(img, (20, 20))
draw = ImageDraw.Draw(bordered, "RGBA")
try:
font = ImageFont.truetype("arial.ttf", 24)
except:
font = ImageFont.load_default()
watermark = f"原创解读 {time.strftime('%Y-%m-%d')}"
bbox = draw.textbbox((0, 0), watermark, font=font)
text_w = bbox[2] - bbox[0]
text_h = bbox[3] - bbox[1]
x = width + 20 - text_w - 10
y = height + 20 - text_h - 10
draw.rectangle((x-6, y-6, x+text_w+6, y+text_h+6), fill=(0, 0, 0, 140))
draw.text((x, y), watermark, font=font, fill=(255, 255, 255, 220))
bordered.save(output_path, quality=92)
return True
except Exception as e:
print(f"图片处理失败 {raw_path}: {e}")
return False
def extract_keyframes(video_path, out_dir):
print("提取并原创化关键帧...")
os.makedirs(out_dir, exist_ok=True)
scene_list = detect(video_path, ContentDetector(threshold=0.42))
clip = VideoFileClip(video_path)
processed_paths = []
try:
for i, scene in enumerate(scene_list):
if len(processed_paths) >= MAX_KEYFRAMES:
break
mid_sec = (scene[0].get_seconds() + scene[1].get_seconds()) / 2
frame = clip.get_frame(mid_sec)
raw_path = os.path.join(out_dir, f"raw_{i:03d}.jpg")
Image.fromarray(frame).save(raw_path)
proc_path = os.path.join(out_dir, f"keyframe_{i:03d}_orig.jpg")
if process_keyframe_for_originality(raw_path, proc_path):
processed_paths.append(proc_path)
else:
processed_paths.append(raw_path)
finally:
clip.close()
print(f"提取并处理到 {len(processed_paths)} 张原创关键帧")
return processed_paths
def generate_article(transcript, keyframes):
print(f"调用 {LLM_MODEL} 生成原创图文文章(无字数限制)...")
kf_absolute_paths = [f"file://{os.path.abspath(kf)}" for kf in keyframes]
kf_names = [Path(k).name for k in keyframes]
kf_descriptions = [f"原创处理画面 {name}:视频核心时刻艺术化呈现" for name in kf_names]
kf_md_list = [f"" for desc, path in zip(kf_descriptions, kf_absolute_paths)]
kf_md_block = "\n\n".join(kf_md_list)
prompt = f"""你是一位极具原创精神的中文内容创作者和深度解读专家。请基于以下视频完整字幕,撰写一篇**完全原创**的图文文章。
核心原则:
- 100%原创:不得直接复制或照搬字幕原文、金句,所有内容用你自己的话重新组织、润色、扩展、变形表达。
- 意思保持完全一致:保留视频所有核心观点、事实、逻辑顺序、关键信息,不增减、不扭曲原意。
- 表达方式全面变化:使用多样句式、丰富词汇、不同叙述角度,避免任何雷同表述。
- 内容最大化:无字数上限,尽可能详细、深入、富有洞见,加入合理分析、背景补充、延伸思考、实用价值。
- 图文结合:在文章合适位置自然插入关键帧图片,使用 Markdown 格式:,描述要贴合上下文。
- 结构清晰:标题极具吸引力;开头引言300–800字;正文8–12个小标题;结尾深刻总结+行动号召。
- 输出纯 Markdown 格式,无任何前言、后语或说明。
完整视频字幕:
{transcript}
关键帧图片(已原创处理,按顺序):
{kf_md_block}
关键帧文件名对应顺序:
{', '.join(kf_names)}
现在开始创作一篇**高度原创、表达全新**的深度图文文章。"""
response = ollama.chat(
model=LLM_MODEL,
messages=[{"role": "user", "content": prompt}],
options={"temperature": 0.5, "num_predict": -1}
)
return response['message']['content']
def main():
start = time.time()
base = Path(VIDEO_PATH).stem
audio = f"{OUTPUT_DIR}/{base}.mp3"
kf_dir = f"{OUTPUT_DIR}/{base}_keyframes"
os.makedirs(OUTPUT_DIR, exist_ok=True)
os.makedirs(kf_dir, exist_ok=True)
extract_audio(VIDEO_PATH, audio)
transcript = transcribe(audio)
keyframes = extract_keyframes(VIDEO_PATH, kf_dir)
article = generate_article(transcript, keyframes)
md_path = f"{OUTPUT_DIR}/{base}_article_full.md"
with open(md_path, "w", encoding="utf-8") as f:
f.write(article)
print(f"\n完成!原创图文文章保存至:{md_path}")
print(f"总耗时:{(time.time() - start) / 60:.1f} 分钟")
if __name__ == "__main__":
main()第三步 运行前最后检查
1 激活环境:
source /Users/dev/gitrepo/llm/ollama/venv/bin/activate2 确认关键依赖:
pip list | grep -E "faster-whisper|scenedetect|moviepy|pillow|ollama|opencv"
3 确认 Whisper 模型已预下载:
ls -la ~/.cache/huggingface/hub/models--dropbox-dash--faster-whisper-large-v3-turbo
4 运行脚本:
/Users/dev/gitrepo/llm/ollama/venv/bin/python /Users/dev/gitrepo/llm/ollama/video_to_article_m2.py输出结果
音频:output_m2/12.mp3
关键帧(原创处理后):output_m2/12_keyframes/keyframe_xxx_orig.jpg
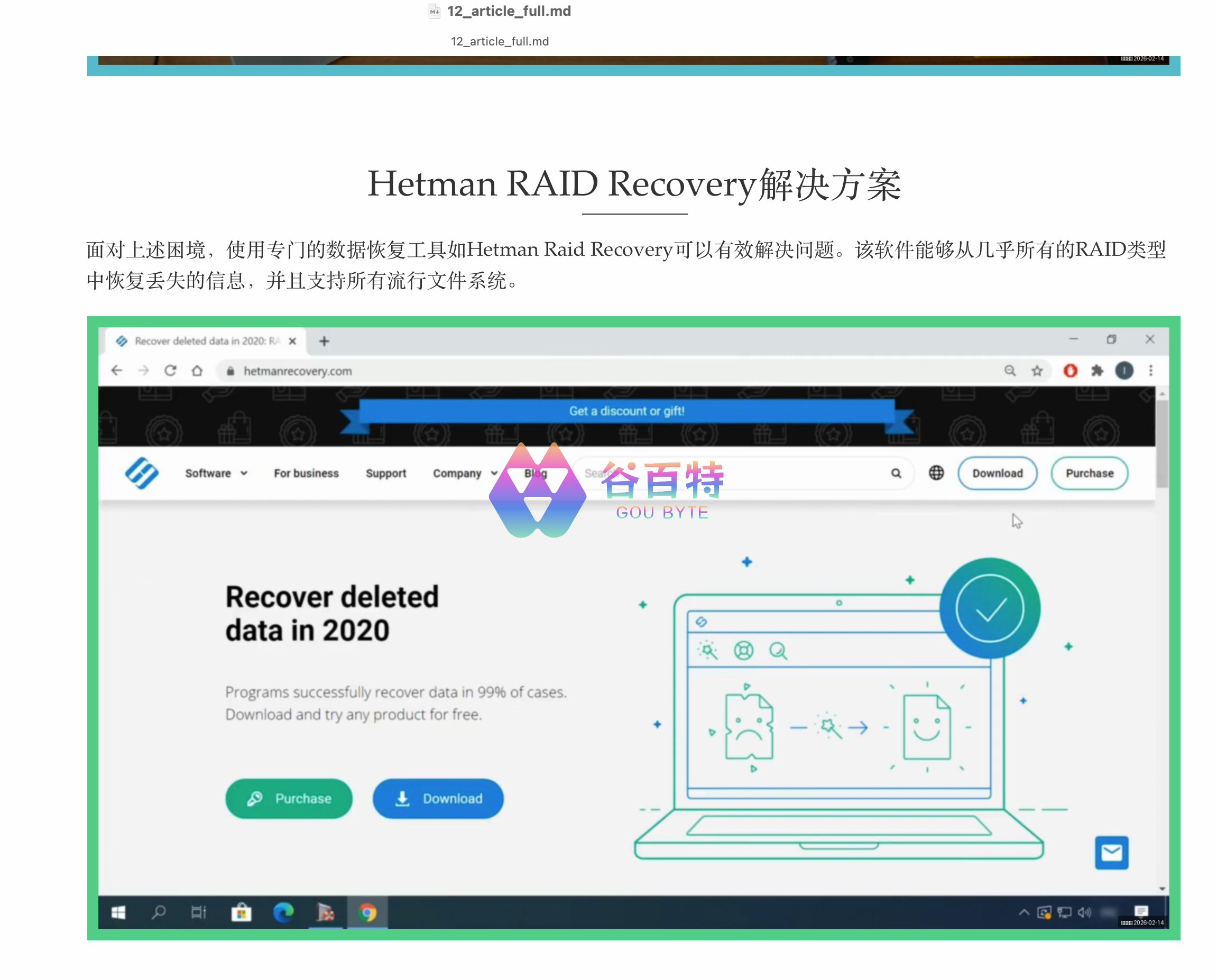
文章:output_m2/12_article_full.md(用 Typora 打开即可看到图文并茂效果)
如下图:

5 文章展示
使用 Typora 打开,如下图:
评论区